小技巧:用WINDOW子句干掉重复的OVER
window子句是什么?
最近整理题目的时候,发现spark支持window子句,window就是窗口函数中over后面的部分,window子句就是把这个部分起个名,后面直接用。我们先来看一个简单的例子。使用 db_interview_cj(高频题目) 中的t3_salary表,对应题目是 去掉最大最小值的部门平均薪水
表内数据如下
+---------+------------+-----------+
| emp_id | depart_id | salary |
+---------+------------+-----------+
| 1001 | 1 | 5000.00 |
| 1002 | 1 | 10000.00 |
| 1003 | 1 | 20000.00 |
| 1004 | 1 | 30000.00 |
| 1005 | 1 | 6000.00 |
| 1006 | 1 | 10000.00 |
| 1007 | 1 | 11000.00 |
| 1008 | 2 | 3000.00 |
| 1009 | 2 | 7000.00 |
| 1010 | 2 | 9000.00 |
| 1011 | 2 | 30000.00 |
+---------+------------+-----------+
计算每个部门从高到低的薪资排名
spark常规写法
select
emp_id,
depart_id,
salary,
row_number()over(partition by depart_id order by salary desc) as rn
from t3_salary;
执行结果
+---------+------------+-----------+-----+
| emp_id | depart_id | salary | rn |
+---------+------------+-----------+-----+
| 1004 | 1 | 30000.00 | 1 |
| 1003 | 1 | 20000.00 | 2 |
| 1007 | 1 | 11000.00 | 3 |
| 1002 | 1 | 10000.00 | 4 |
| 1006 | 1 | 10000.00 | 5 |
| 1005 | 1 | 6000.00 | 6 |
| 1001 | 1 | 5000.00 | 7 |
| 1011 | 2 | 30000.00 | 1 |
| 1010 | 2 | 9000.00 | 2 |
| 1009 | 2 | 7000.00 | 3 |
| 1008 | 2 | 3000.00 | 4 |
+---------+------------+-----------+-----+
11 rows selected (7.623 seconds)(https://www.dwsql.com)
window子句写法
select
emp_id,
depart_id,
salary,
row_number()over (salary_desc) as rn
from t3_salary
window salary_desc as (partition by depart_id order by salary desc);
执行结果
+---------+------------+-----------+-----+
| emp_id | depart_id | salary | rn |
+---------+------------+-----------+-----+
| 1004 | 1 | 30000.00 | 1 |
| 1003 | 1 | 20000.00 | 2 |
| 1007 | 1 | 11000.00 | 3 |
| 1002 | 1 | 10000.00 | 4 |
| 1006 | 1 | 10000.00 | 5 |
| 1005 | 1 | 6000.00 | 6 |
| 1001 | 1 | 5000.00 | 7 |
| 1011 | 2 | 30000.00 | 1 |
| 1010 | 2 | 9000.00 | 2 |
| 1009 | 2 | 7000.00 | 3 |
| 1008 | 2 | 3000.00 | 4 |
+---------+------------+-----------+-----+
11 rows selected (0.309 seconds)(https://www.dwsql.com)
我们可以看到,window子句就是把over后面的部分单独拿出来,然后取个名字,在使用的时候直接使用这个名字即可。好像也没有特别明显的优势。但是在实际工作中如果我们存在大量的窗口函数,这个功能就会使代码更加简洁与易维护; 假设我们使用row_number,rank,dense_rank,percent_rank等窗口函数,分别对比排名,那么两段SQL分别如下:
spark常规写法
select
emp_id,
depart_id,
salary,
row_number()over(partition by depart_id order by salary desc) as rn,
rank()over(partition by depart_id order by salary desc) as rk,
dense_rank()over(partition by depart_id order by salary desc) as drk,
percent_rank()over(partition by depart_id order by salary desc) as pr
from t3_salary;
执行结果
+---------+------------+-----------+-----+-----+------+----------------------+
| emp_id | depart_id | salary | rn | rk | drk | pr |
+---------+------------+-----------+-----+-----+------+----------------------+
| 1004 | 1 | 30000.00 | 1 | 1 | 1 | 0.0 |
| 1003 | 1 | 20000.00 | 2 | 2 | 2 | 0.16666666666666666 |
| 1007 | 1 | 11000.00 | 3 | 3 | 3 | 0.3333333333333333 |
| 1002 | 1 | 10000.00 | 4 | 4 | 4 | 0.5 |
| 1006 | 1 | 10000.00 | 5 | 4 | 4 | 0.5 |
| 1005 | 1 | 6000.00 | 6 | 6 | 5 | 0.8333333333333334 |
| 1001 | 1 | 5000.00 | 7 | 7 | 6 | 1.0 |
| 1011 | 2 | 30000.00 | 1 | 1 | 1 | 0.0 |
| 1010 | 2 | 9000.00 | 2 | 2 | 2 | 0.3333333333333333 |
| 1009 | 2 | 7000.00 | 3 | 3 | 3 | 0.6666666666666666 |
| 1008 | 2 | 3000.00 | 4 | 4 | 4 | 1.0 |
+---------+------------+-----------+-----+-----+------+----------------------+
11 rows selected (0.546 seconds)(https://www.dwsql.com)
window子句写法
select
emp_id,
depart_id,
salary,
row_number()over (salary_desc) as rn,
rank()over (salary_desc) as rk,
dense_rank()over (salary_desc) as drk,
percent_rank()over (salary_desc) as pr
from t3_salary
window salary_desc as (partition by depart_id order by salary desc);
执行结果
+---------+------------+-----------+-----+-----+------+----------------------+
| emp_id | depart_id | salary | rn | rk | drk | pr |
+---------+------------+-----------+-----+-----+------+----------------------+
| 1004 | 1 | 30000.00 | 1 | 1 | 1 | 0.0 |
| 1003 | 1 | 20000.00 | 2 | 2 | 2 | 0.16666666666666666 |
| 1007 | 1 | 11000.00 | 3 | 3 | 3 | 0.3333333333333333 |
| 1002 | 1 | 10000.00 | 4 | 4 | 4 | 0.5 |
| 1006 | 1 | 10000.00 | 5 | 4 | 4 | 0.5 |
| 1005 | 1 | 6000.00 | 6 | 6 | 5 | 0.8333333333333334 |
| 1001 | 1 | 5000.00 | 7 | 7 | 6 | 1.0 |
| 1011 | 2 | 30000.00 | 1 | 1 | 1 | 0.0 |
| 1010 | 2 | 9000.00 | 2 | 2 | 2 | 0.3333333333333333 |
| 1009 | 2 | 7000.00 | 3 | 3 | 3 | 0.6666666666666666 |
| 1008 | 2 | 3000.00 | 4 | 4 | 4 | 1.0 |
+---------+------------+-----------+-----+-----+------+----------------------+
11 rows selected (0.281 seconds)(https://www.dwsql.com)
可以多个子句使用
可以写多个不同的子句,每个子句对应一个窗口规范,然后在函数中使用这个名字即可。 例如:想要正序和倒序
select
emp_id,
depart_id,
salary,
row_number()over (salary_asc) as rn_asc,
row_number()over (salary_desc) as rn_desc
from t3_salary
window
salary_asc as (partition by depart_id order by salary),
salary_desc as (partition by depart_id order by salary desc);
执行结果
+---------+------------+-----------+---------+----------+
| emp_id | depart_id | salary | rn_asc | rn_desc |
+---------+------------+-----------+---------+----------+
| 1004 | 1 | 30000.00 | 7 | 1 |
| 1003 | 1 | 20000.00 | 6 | 2 |
| 1007 | 1 | 11000.00 | 5 | 3 |
| 1002 | 1 | 10000.00 | 3 | 4 |
| 1006 | 1 | 10000.00 | 4 | 5 |
| 1005 | 1 | 6000.00 | 2 | 6 |
| 1001 | 1 | 5000.00 | 1 | 7 |
| 1011 | 2 | 30000.00 | 4 | 1 |
| 1010 | 2 | 9000.00 | 3 | 2 |
| 1009 | 2 | 7000.00 | 2 | 3 |
| 1008 | 2 | 3000.00 | 1 | 4 |
+---------+------------+-----------+---------+----------+
11 rows selected (0.306 seconds)(https://www.dwsql.com)
window子句带来的好处
- 代码简洁,尤其是在需要多个窗口函数的时候。
- 多个不同逻辑的窗口函数,尤其是分组和排序字段较多时,阅读更加清晰;
- 修改分组字段或者排序字段时,只需要修改window子句,简洁方便,更不易出错。
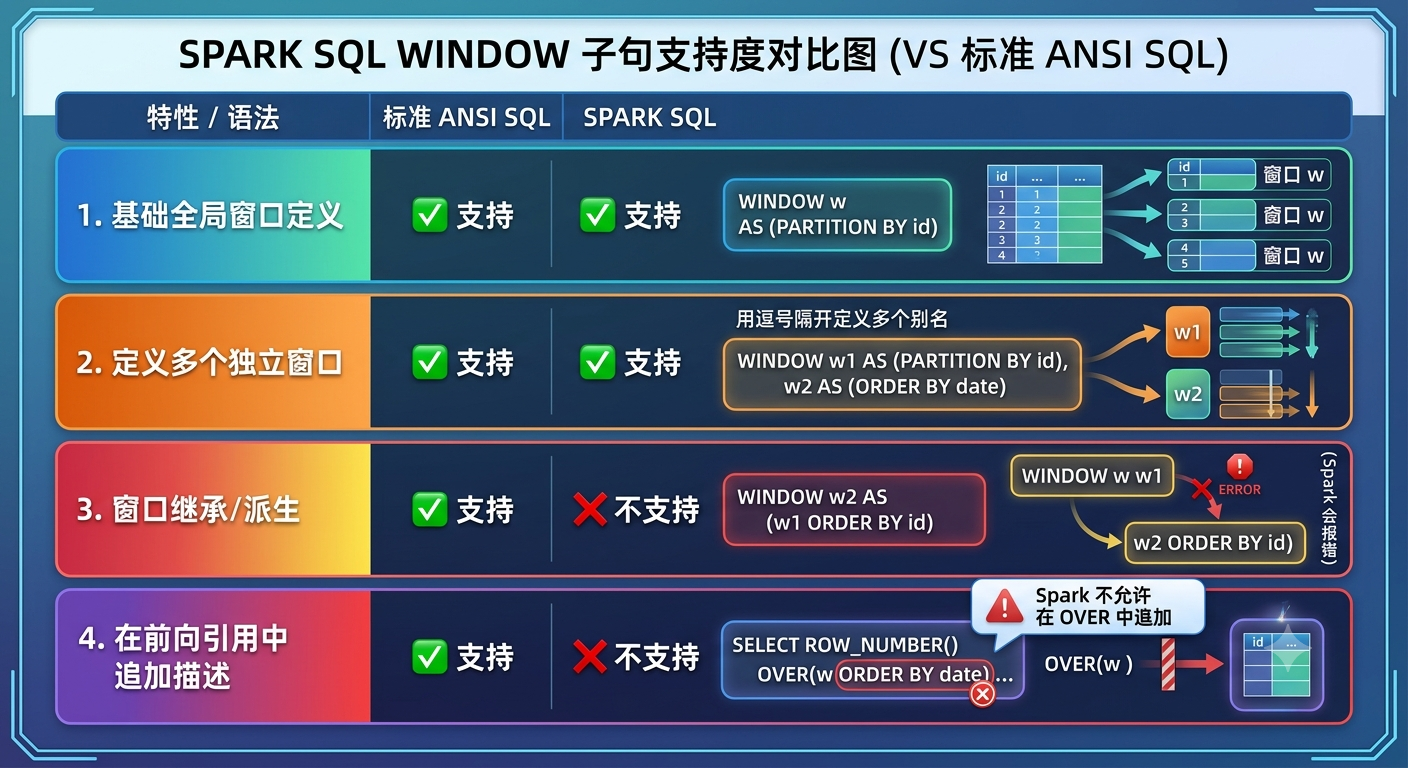
ANSI SQL标准 与 Spark SQL 之间的差异
| 特性 / 语法 | 标准 ANSI SQL 支持度 | Spark SQL 支持度 | 示例与说明 |
|---|---|---|---|
| 基础全局窗口定义 | ✅ 支持 | ✅ 支持 | WINDOW w AS (PARTITION BY id) |
| 定义多个独立窗口 | ✅ 支持 | ✅ 支持 | 用逗号隔开定义多个别名 |
| 窗口继承/派生 | ✅ 支持 | ❌ 不支持 | w2 AS (w1 ...) (Spark 会报错) |
| 在前向引用中追加描述 | ✅ 支持 | ❌ 不支持 | ROW_NUMBER() OVER (w ...) (Spark 不允许在 OVER 中追加) |
写的时候注意几个坑
- 窗口名别跟列名、别名重了,会报歧义错。养成加前缀的习惯,比如
w_rank、w_dept。 WINDOW子句的位置不能随便放——它必须在ORDER BY前面。- over后面带括号,虽然只有一个window子句的时候,不写括号也能执行,但是当有两个及以上时不带括号直接报错。
row_number()over (salary_asc),而不是row_number()over salary_desc。
📱关注公众号
「数据仓库技术」文章同步更新,不错过每一篇干货

💬加群交流
备注「数据仓库技术」加入社群,每日一道大厂SQL真题
