SQL 去掉最高最低值的部门平均薪水:窗口函数排除极值(字节跳动面试题)
一、题目
有员工薪资表t8_salary,包含员工ID(emp_id),部门ID(depart_id),薪水(salary),请计算去除最高最低薪资后的平均薪水;(每个部门员工数不少于5人)
仅用一个开窗函数
+---------+------------+-----------+
| emp_id | depart_id | salary |
+---------+------------+-----------+
| 1001 | 1 | 5000.00 |
| 1002 | 1 | 10000.00 |
| 1003 | 1 | 20000.00 |
| 1004 | 1 | 30000.00 |
| 1005 | 1 | 6000.00 |
| 1006 | 1 | 10000.00 |
| 1007 | 1 | 11000.00 |
| 1008 | 2 | 3000.00 |
| 1009 | 2 | 7000.00 |
| 1010 | 2 | 9000.00 |
| 1011 | 2 | 30000.00 |
| 1012 | 2 | 31000.00 |
+---------+------------+-----------+
二、分析
这个题目我们写过很多了,下面列出历史题目,大家可以复习。 但是本次题目要求仅能使用一次开窗函数。在这个要求上,难度就直接提升了。在这个要求下,我不介意给其难度提升到5星。
- 去掉最大最小值的部门平均薪水
- 小红书大数据面试SQL-查询每个用户的第一条和最后一条记录
- 查询前2大和前2小用户并有序拼接
| 维度 | 评分 |
|---|---|
| 题目难度 | ⭐️⭐️⭐️⭐️⭐️ |
| 题目清晰度 | ⭐️⭐️⭐️⭐️⭐️ |
| 业务常见度 | ⭐️⭐️⭐️⭐️ |
三、SQL
2.方案二 该方案通过对窗口函数的大小、位置以及对分组排序后开始和结尾处窗口覆盖范围的应用,来处理。这也是这个题目的亮点,定向严格的考察了对开窗函数的理解;
- 先通过count开窗,按照部门分组,窗口大小为 当前行的前一行到当前行的后一行
执行SQL
select emp_id,
depart_id,
salary,
count(1) over (partition by depart_id order by salary rows between 1 preceding and 1 following) as row_cnt
from t8_salary
查询结果
图一我给圈出了第一行、第二行、第三行数据的窗口范围;
观察图二,我们可以看到首行末行的统计结果;
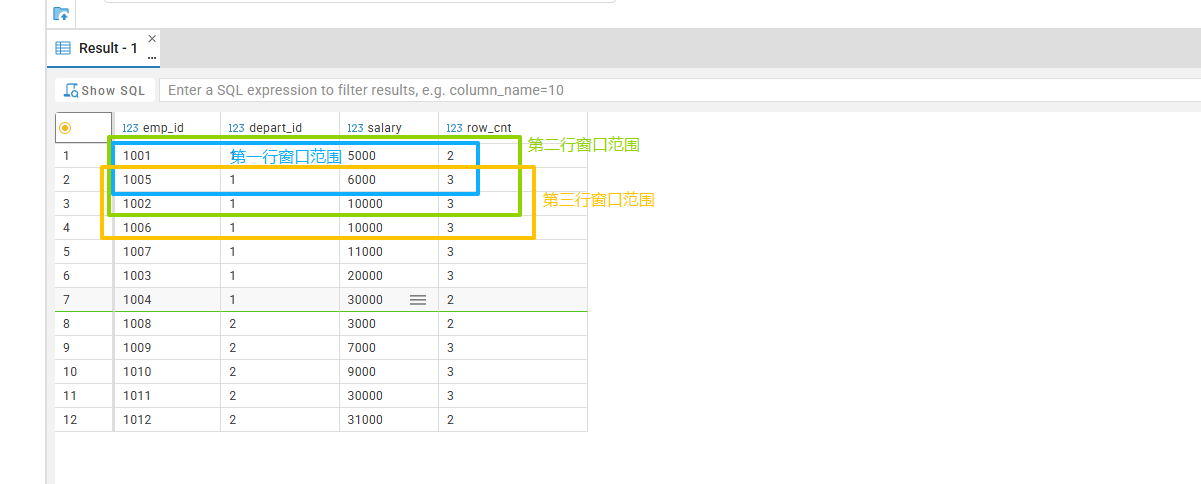
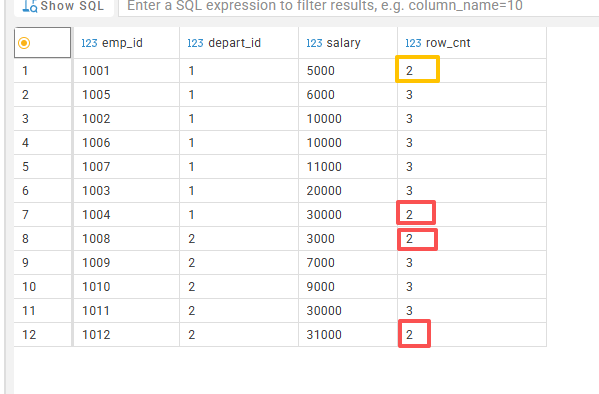
- 限定行数row_cnt = 3 即可得到去掉最大最小记录的数据,计算平均值即可
执行SQL
select depart_id,
avg(salary) as avg_depart_salary
from (select emp_id,
depart_id,
salary,
count(1) over (partition by depart_id order by salary rows between 1 preceding and 1 following) as row_cnt
from t8_salary)
where row_cnt = 3
group by depart_id
查询结果
+------------+--------------------+
| depart_id | avg_depart_salary |
+------------+--------------------+
| 1 | 11400.000000 |
| 2 | 15333.333333 |
+------------+--------------------+
2 rows selected (0.387 seconds)
引伸:去掉薪水最大2人、最小2人的平均薪水
我们将窗口扩大到5,前2行和后两行
执行SQL
select emp_id,
depart_id,
salary,
count(1) over (partition by depart_id order by salary rows between 2 preceding and 2 following) as row_cnt
from t8_salary;
执行结果 我们仅需要限制row_cnt = 5 即可获得目标行
+---------+------------+-----------+----------+
| emp_id | depart_id | salary | row_cnt |
+---------+------------+-----------+----------+
| 1001 | 1 | 5000.00 | 3 |
| 1005 | 1 | 6000.00 | 4 |
| 1002 | 1 | 10000.00 | 5 |
| 1006 | 1 | 10000.00 | 5 |
| 1007 | 1 | 11000.00 | 5 |
| 1003 | 1 | 20000.00 | 4 |
| 1004 | 1 | 30000.00 | 3 |
| 1008 | 2 | 3000.00 | 3 |
| 1009 | 2 | 7000.00 | 4 |
| 1010 | 2 | 9000.00 | 5 |
| 1011 | 2 | 30000.00 | 4 |
| 1012 | 2 | 31000.00 | 3 |
+---------+------------+-----------+----------+
12 rows selected (0.422 seconds)
四、建表语句和数据插入
--建表语句
CREATE TABLE t8_salary (
emp_id bigint,
depart_id bigint,
salary decimal(16,2)
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
--插入数据
insert into t8_salary (emp_id,depart_id,salary)
values
(1001,1,5000.00),
(1002,1,10000.00),
(1003,1,20000.00),
(1004,1,30000.00),
(1005,1,6000.00),
(1006,1,10000.00),
(1007,1,11000.00),
(1008,2,3000.00),
(1009,2,7000.00),
(1010,2,9000.00),
(1011,2,30000.00),
(1012,2,31000.00)
;
📱关注公众号
「数据仓库技术」文章同步更新,不错过每一篇干货

💬加群交流
备注「数据仓库技术」加入社群,每日一道大厂SQL真题
