SQL 窗口函数:16大核心算子动态执行图解
窗口函数之所以难理解易出错,核心原因是数据是死的、SQL是静态的,窗口函数计算过程是动态的,一行行的滚动计算,比较难想清楚。
本文用 16 张动态执行 GIF,把最为常见的窗口函数计算过程一帧一帧拆给你看。所有动画均由 窗口函数可视化播放器 生成,每一帧对应一条数据被计算的瞬间。
阅读建议:先看动图下方的"视觉焦点"提示,盯着指定的变化点观察;理解执行过程后,再点击"详解教程"查看语法细节和场景案例。
先搞懂这三个概念,再看动图
窗口函数的本质一句话说清:在不减少原表行数的前提下,为每一行数据开辟一个独立的"视窗"进行计算。
FUNCTION() OVER (PARTITION BY 分组字段 ORDER BY 排序字段 ROWS/RANGE 窗口边界)
| 核心组件 | 在底层做了什么 |
|---|---|
| PARTITION BY | 切分数据集——像把一条大泳道拆成多条独立泳道,各组之间互不干扰 |
| ORDER BY | 决定每个分区内数据的流动顺序——直接影响排名、位移计算的结果 |
| ROWS / RANGE | 定义当前视窗的物理或逻辑边界——是"从头到当前行",还是"前后各 N 行" |
带着这三个概念往下看,每一张动图都是在演示这三个组件如何合力完成一次计算。
算子分类总览
窗口函数共 16 个核心算子,按计算特性划分为 五大类:
| 分类 | 算子 | 数量 | 一句话概括 |
|---|---|---|---|
| 排名 | ROW_NUMBER RANK DENSE_RANK NTILE | 4 | 为每行数据赋予一个序号 |
| 偏移 | LAG LEAD | 2 | 跨行取值,实现行间计算 |
| 聚合 | SUM AVG COUNT MAX MIN | 5 | 聚合函数在滑动窗口上的动态版本 |
| 首尾定位 | FIRST_VALUE LAST_VALUE NTH_VALUE | 3 | 精准锁定窗口的首行、尾行或第 N 行 |
| 分布 | CUME_DIST PERCENT_RANK | 2 | 计算行在分区中的相对位置比例 |
一、排名函数
排名函数的任务很简单:为分区内的每一行分配一个序号。四个函数的区别只在于两件事——"碰到并列值怎么处理"以及"要不要把数据分桶"。
1.1 ROW_NUMBER — 严格编号,不重不漏
ROW_NUMBER() 从 1 开始,为每一行分配一个唯一的递增序号。即使两行排序字段的值完全相同,编号也不会重复,依次往下排。
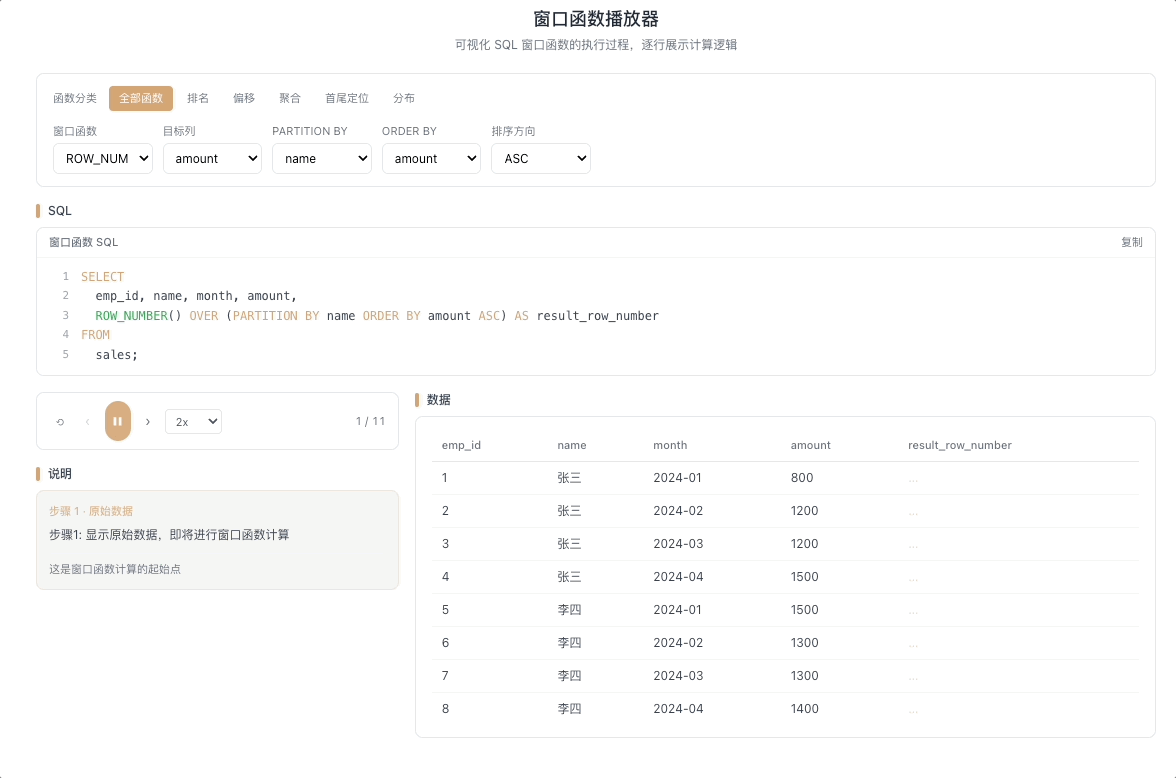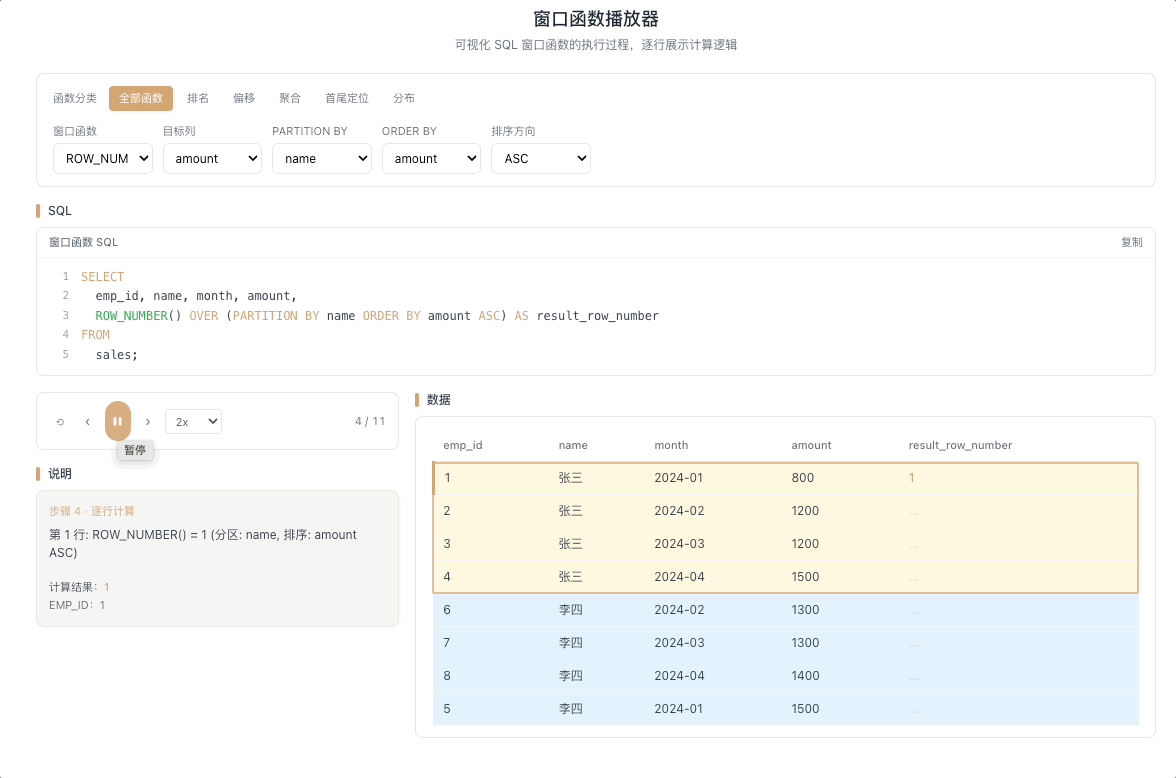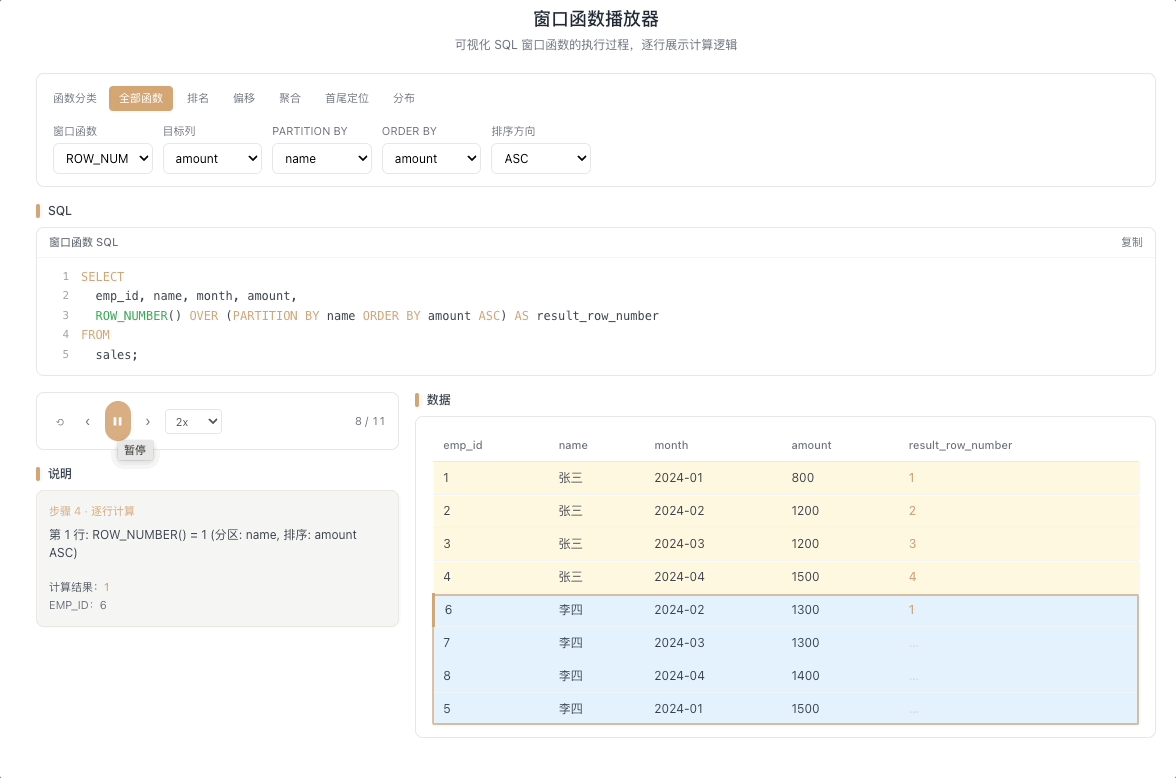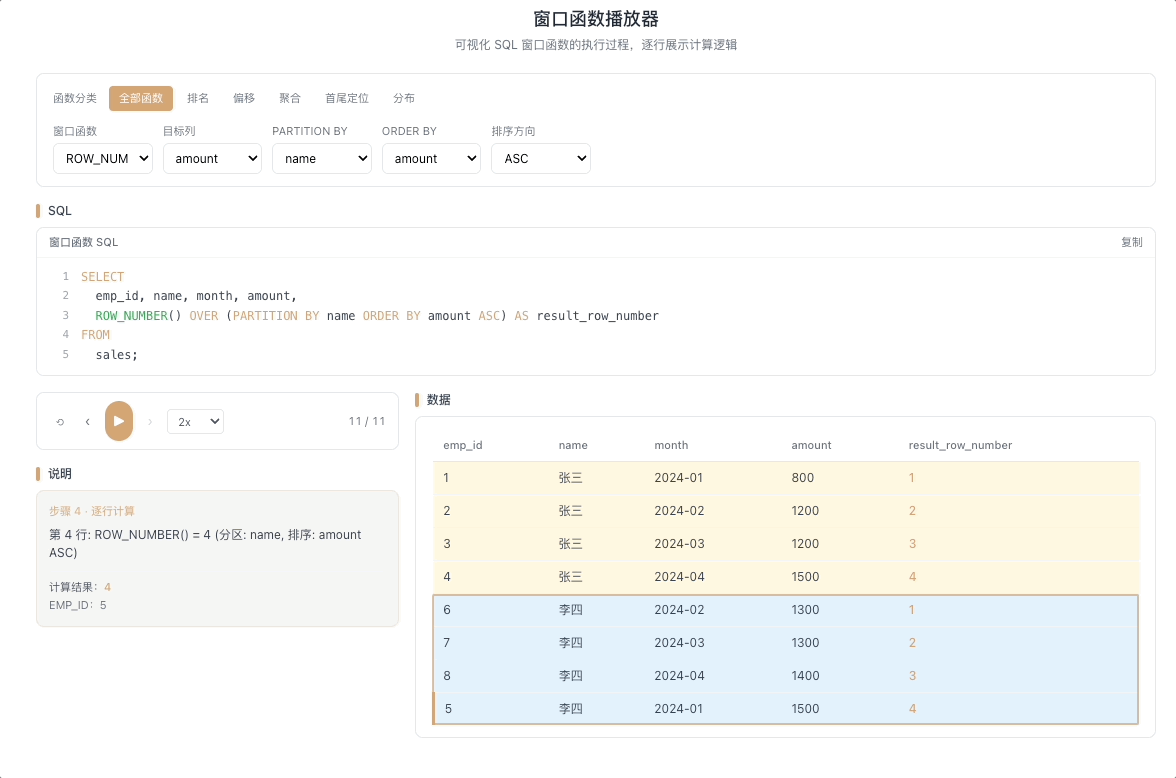
视觉焦点:当光标扫过两行相同数值时,序号一一递增——永远看不到重复数字。
最通用的编号函数,分页、去重(取每组第一条)、生成唯一ID 的首选工具。 [→ 详解教程]
1.2 RANK — 并列跳号
RANK() 遇到并列值时分配相同序号,但后续序号会产生空缺。两个并列第 2 名后面,下一个就是第 4 名——第 3 名被"吃掉"了。
![]()
视觉焦点:关注并列出现时,光标给出相同的数字;紧接着下一个序号突然跳空,中间缺了一个数。
适用于需要体现"有空缺"的排名场景,如考试成绩排名、竞赛名次。 [→ 详解教程]
1.3 DENSE_RANK — 并列不跳号
DENSE_RANK() 同样是并列给相同序号,但下一个序号不跳空。两个并列第 2 名后面紧紧跟着第 3 名——保持紧凑的梯队感。
![]()
视觉焦点:并列发生后,下一个数字紧随其后,排名序列始终保持连续,不会出现数字断层。
适用于排行榜等需要"连续排名"的场景——用户只关心自己是第几名,不关心前面并列了多少人。 [→ 详解教程]
1.4 NTILE — 均匀分桶
NTILE(N) 将分区内的数据尽可能均匀地分配到 N 个桶中,返回每行所属的桶编号(1 到 N)。当数据量不能被 N 整除时,前面的桶会多分一条。
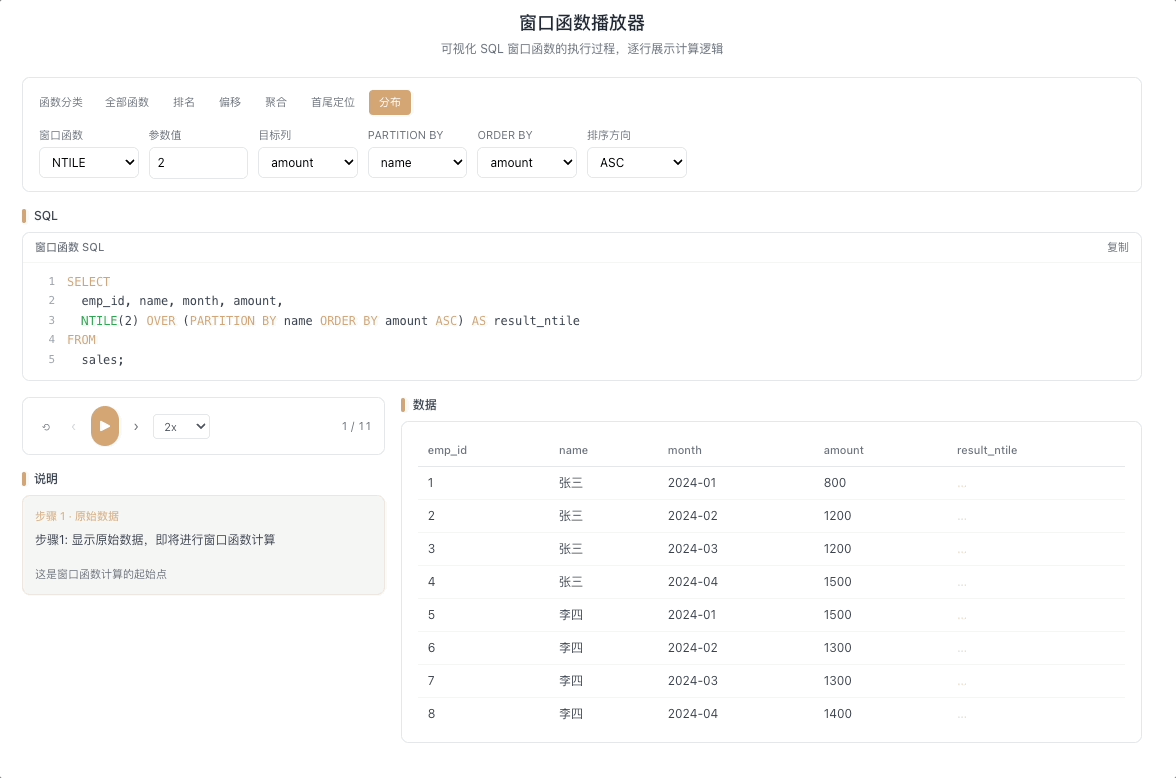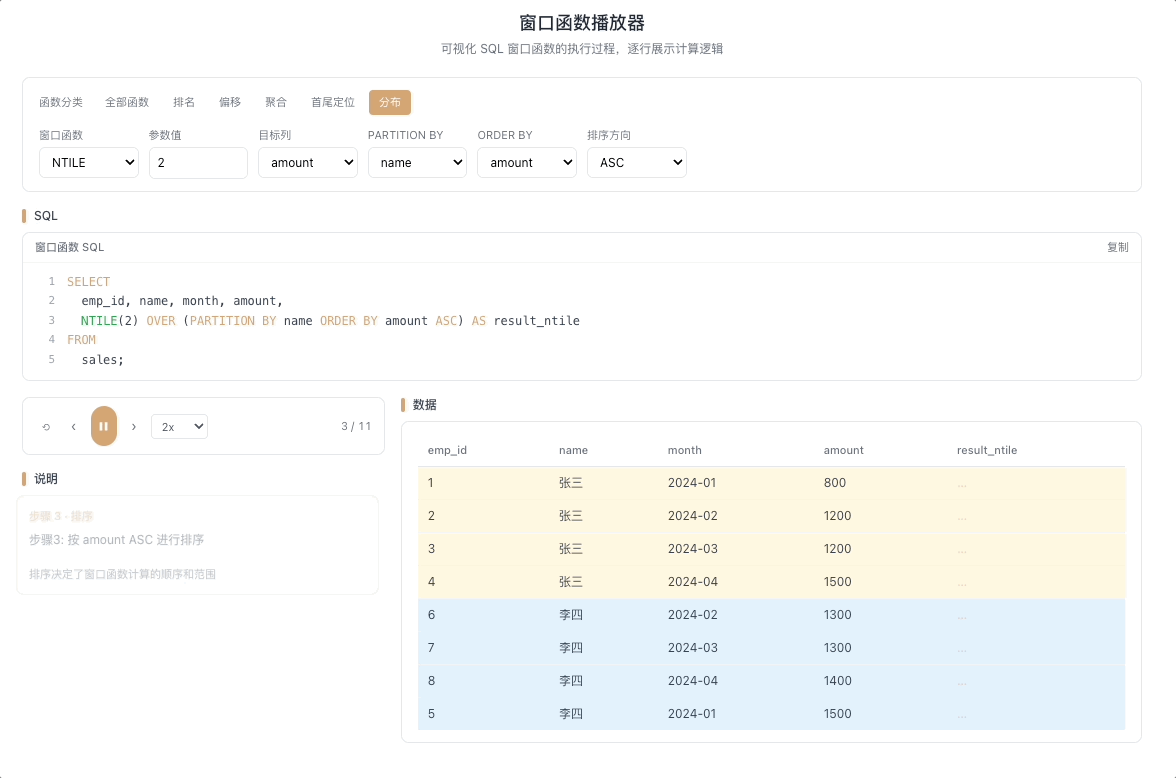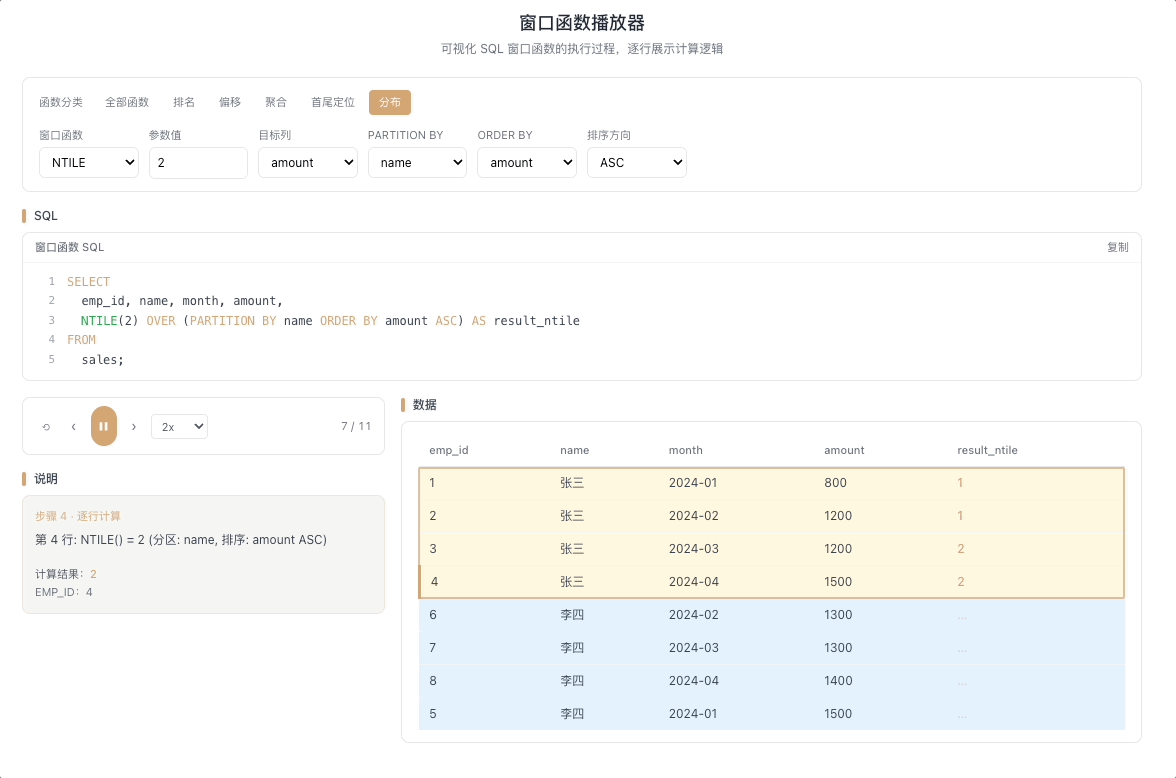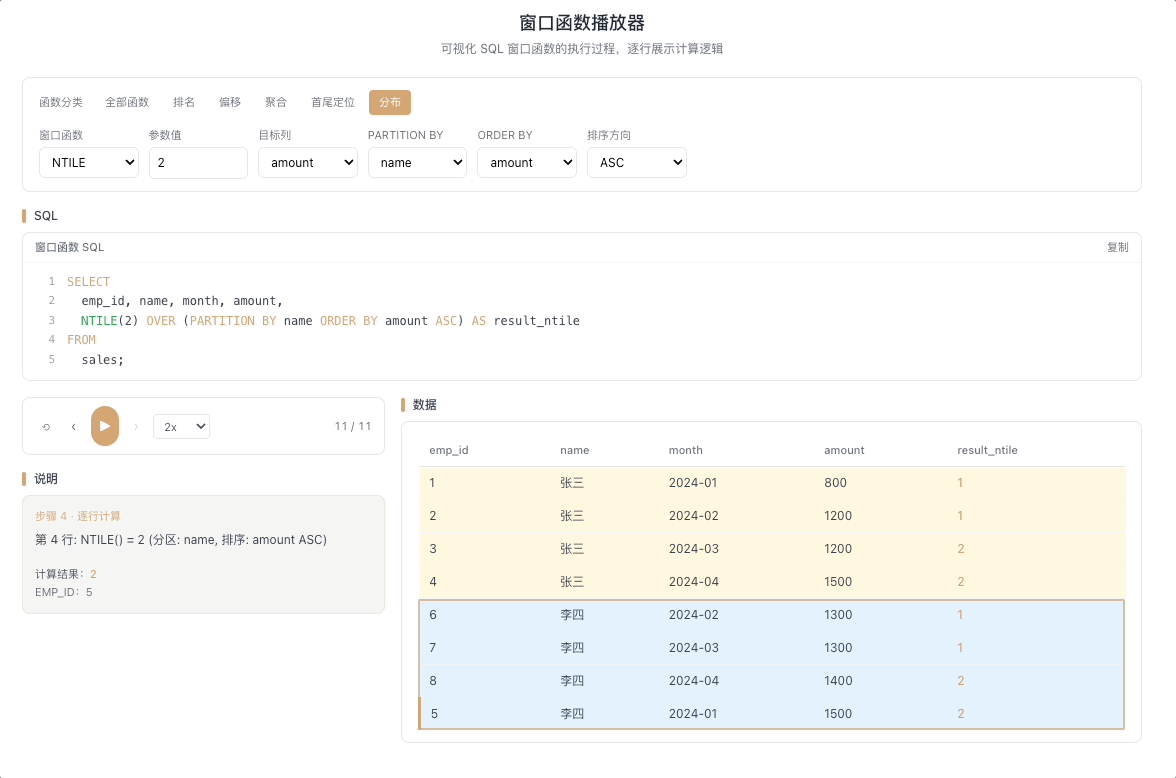
视觉焦点:观察数据如何被按顺序分批装入标有 1、2、3...N 的桶中,每装够一批就切换到下一个桶号。
数据分层、等频分箱、按比例抽样的核心工具。 [→ 详解教程]
二、偏移函数
偏移函数的核心价值在于打破行与行之间的隔离墙——不必写自连接(Self-Join),直接就能从当前行出发,向上或向下抓取指定行的数据。环比、同比、留存分析的基本功全在这两个函数上。
2.1 LAG — 向前取值
LAG(expr, N, default) 返回当前行往前 N 行的 expr 值。往前 N 行不存在时返回 default。就像回头望一眼走过的路——"上一行的值是多少?"
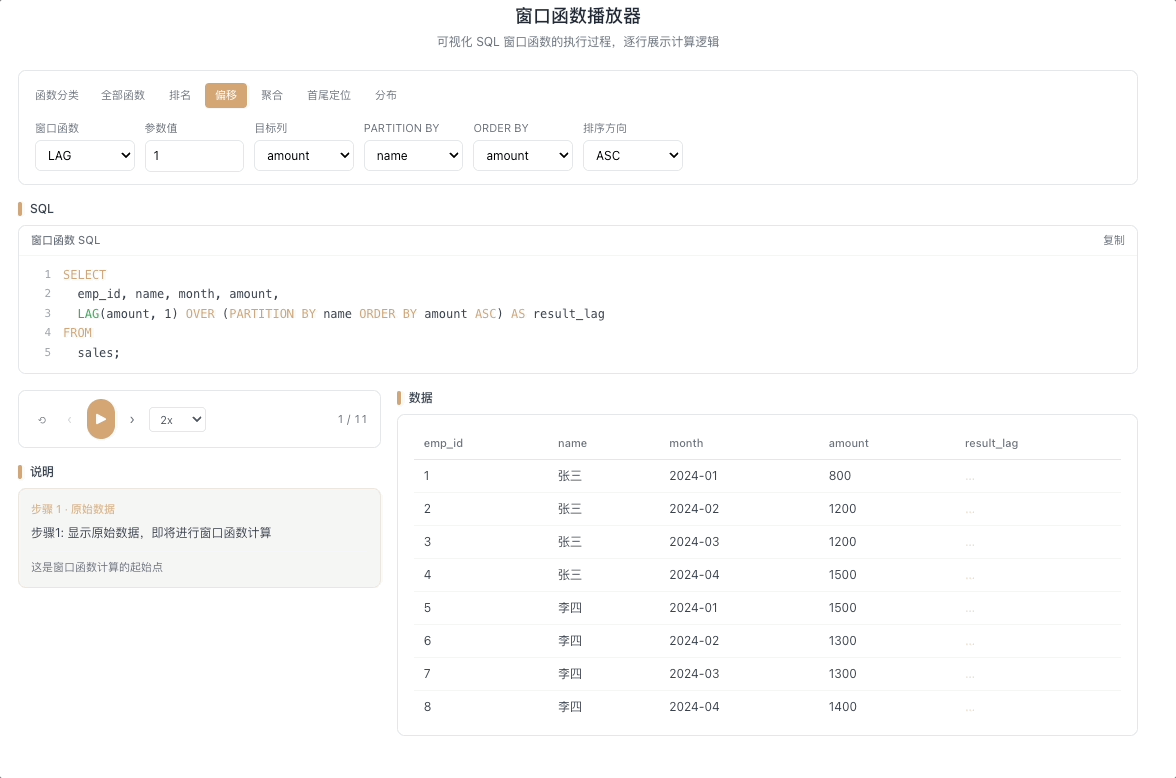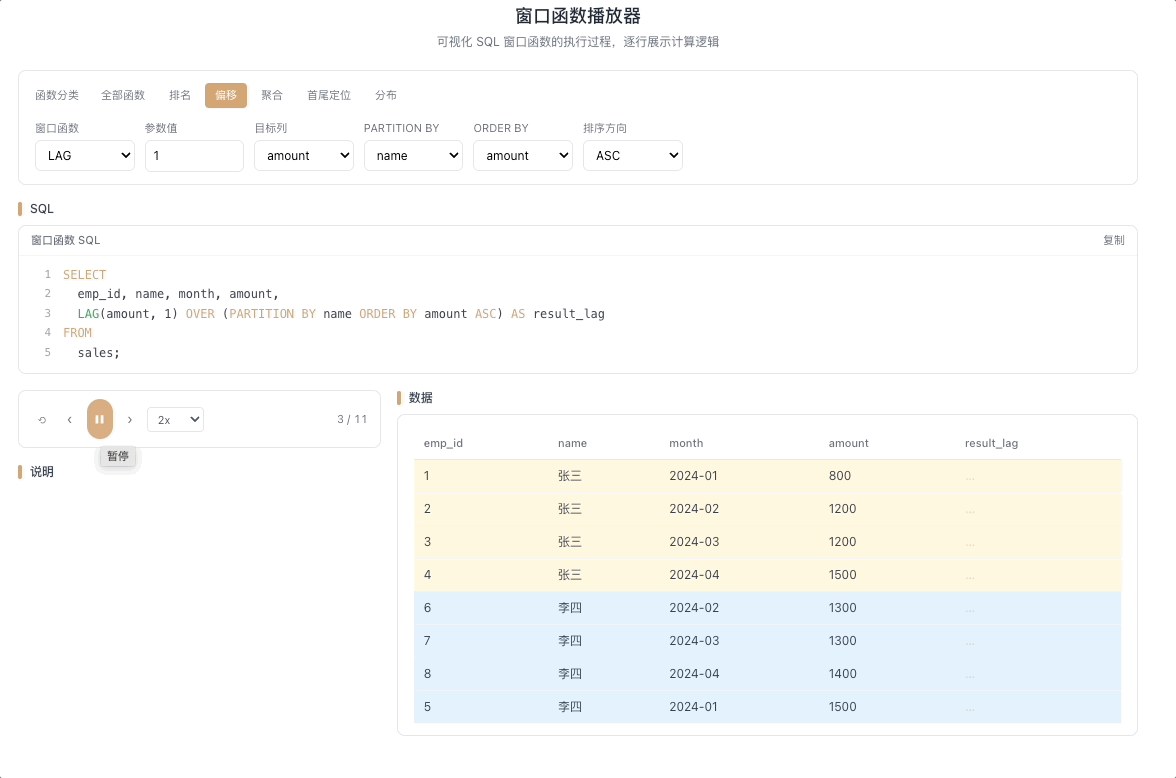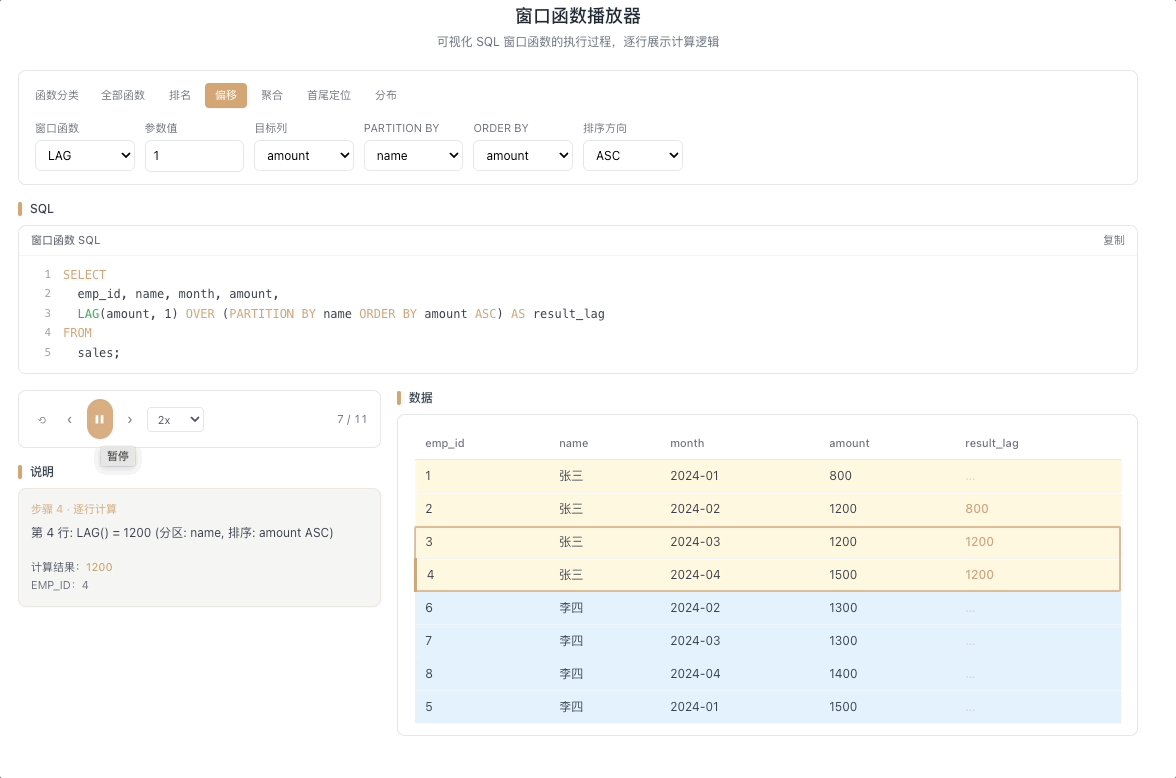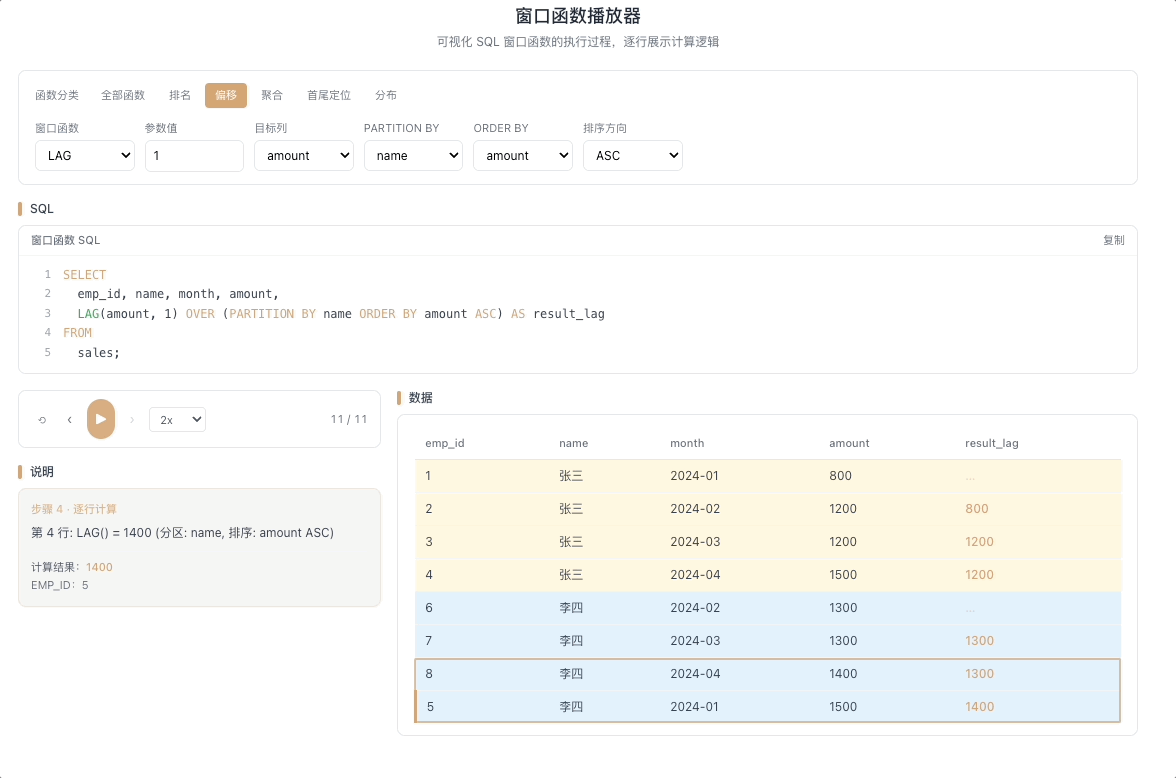
视觉焦点:视窗指针向上延伸,把前一行(或前 N 行)的数据值复制并填入当前行,上方数据像水流一样向下"渗透"。
计算环比增长的核心:
(当前值 - LAG(当前值, 1)) / LAG(当前值, 1)。 [→ 详解教程]
2.2 LEAD — 向后取值
LEAD(expr, N, default) 返回当前行往后 N 行的 expr 值。往后 N 行不存在时返回 default。与 LAG 互为镜像——一个回望,一个前瞻。
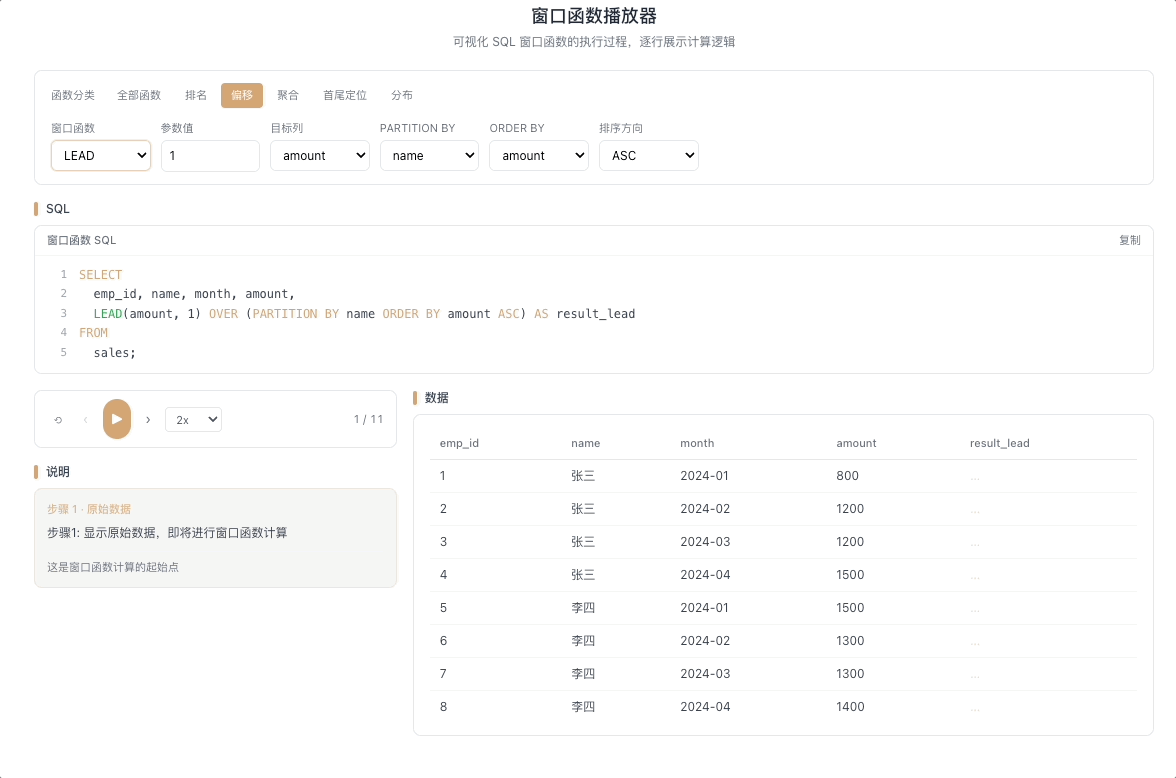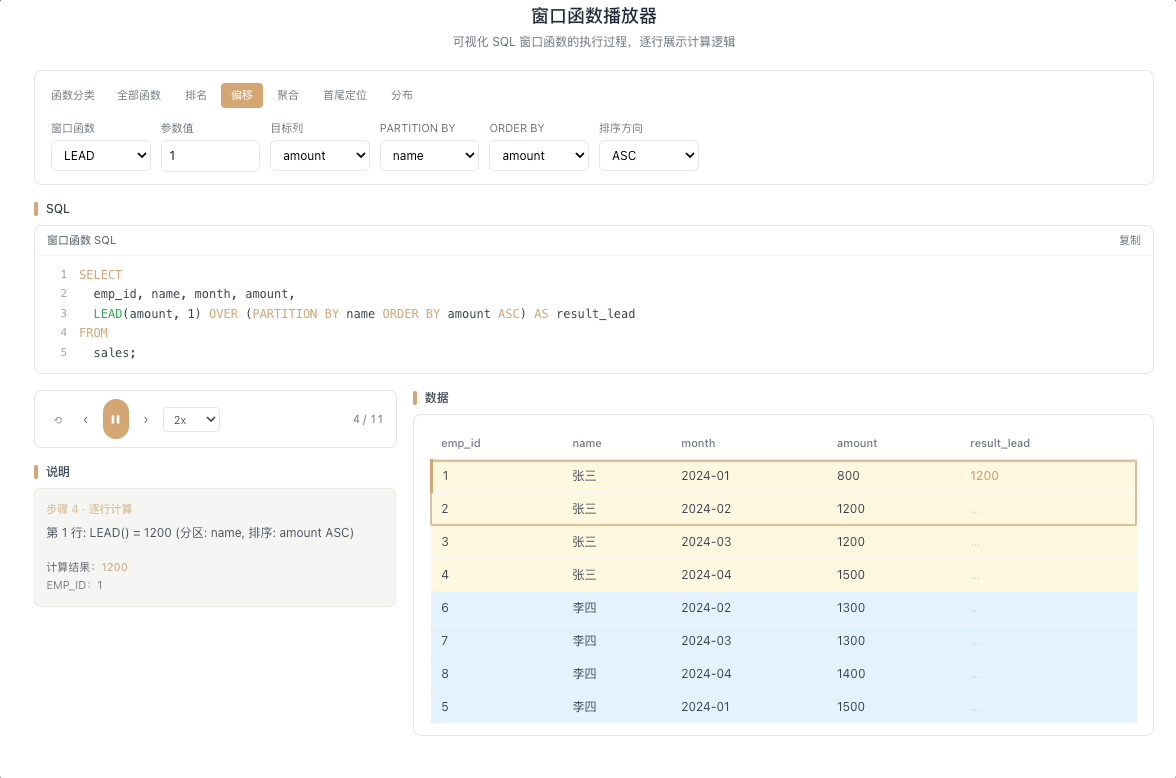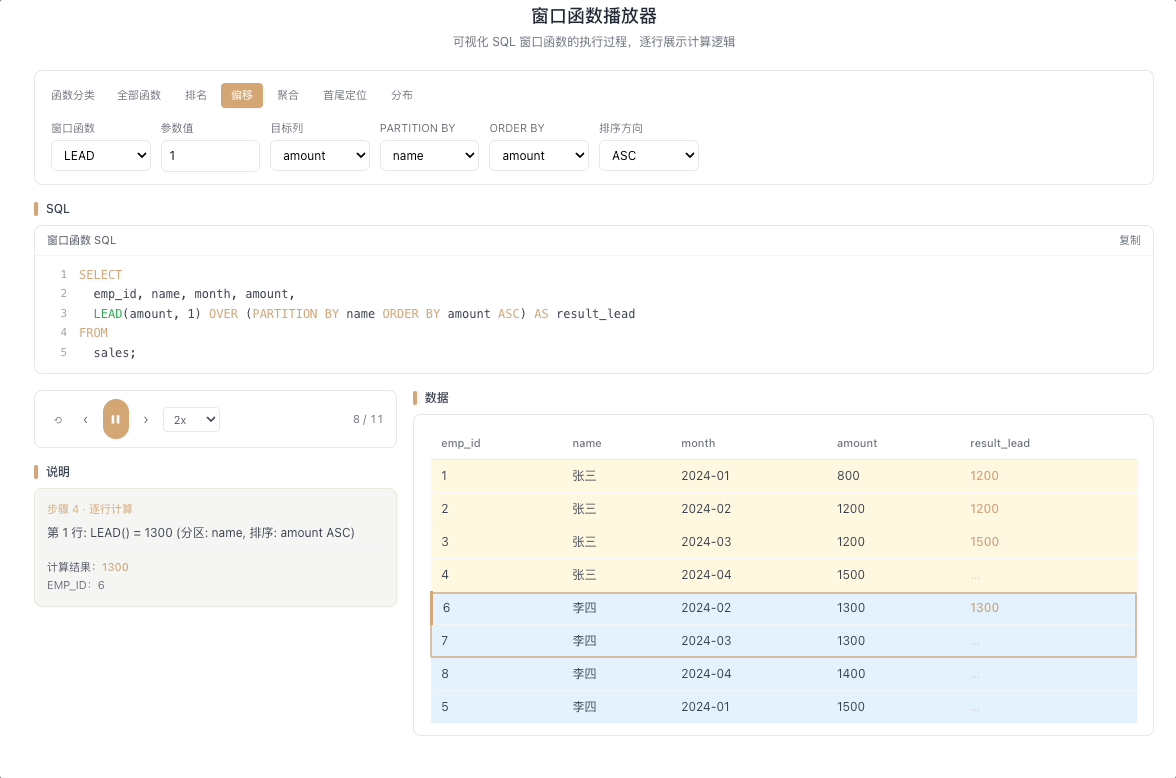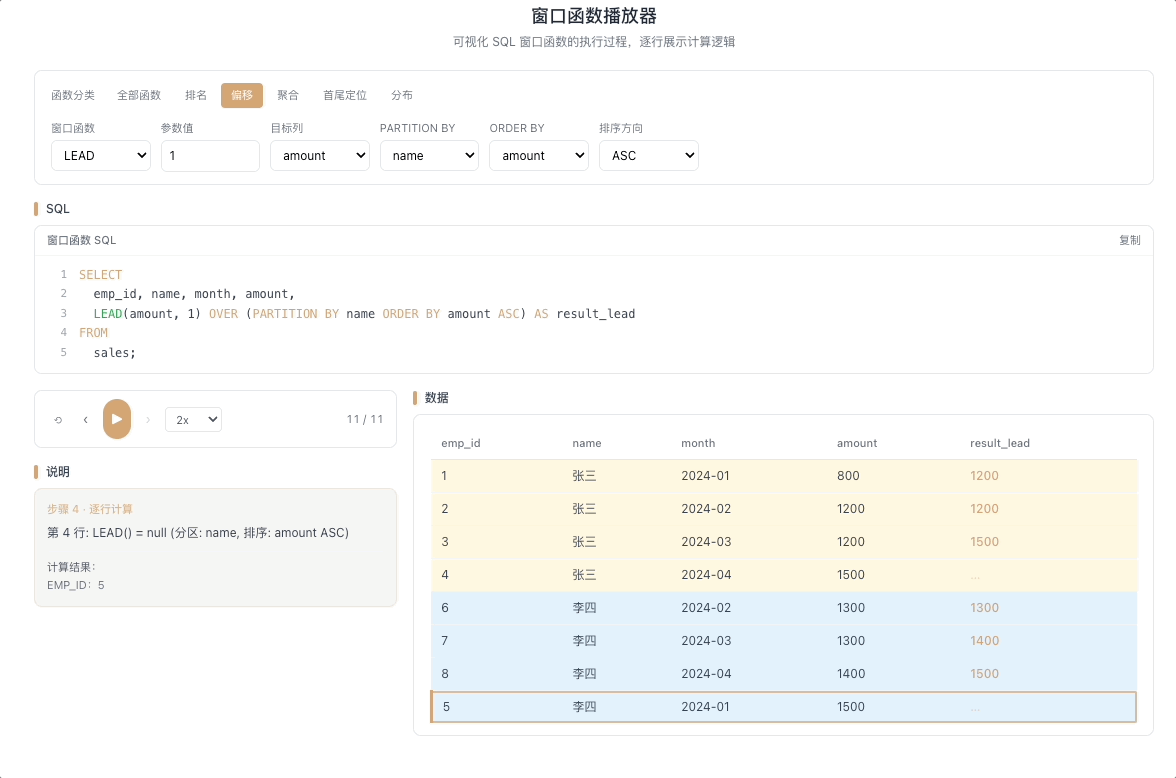
视觉焦点:视窗指针向下探查,提前抓取未来行的数据到当前行,像一种"数据穿越"——当前行提前看到了后面的值。
适合"距离下一个目标还差多少"这类前瞻性分析。 [→ 详解教程]
三、聚合函数
当普通的聚合函数(SUM、AVG、COUNT、MAX、MIN)遇上 OVER() 子句,它们就不再输出单一的汇总值,而是变成了一台随着行标志逐行滑动的"数据扫描仪"——每行都有自己的聚合结果,原始行一条不少。
聚合范围由三个因素共同决定:
- 不排序 → 全分区聚合(每行的结果都一样,等于 GROUP BY)
- 排序 + 不指定窗口帧 → 从分区起点累加到当前行(累计效果)
- 排序 + 指定窗口帧 → 按帧定义精确控制聚合范围(如"前后各 3 行")
3.1 SUM OVER — 累计求和 / 移动求和
SUM() OVER(...) 在窗口帧范围内求和。最典型的用法是累计求和——每一行的结果等于从分区起点到当前行所有值的总和,像滚雪球一样越滚越大。
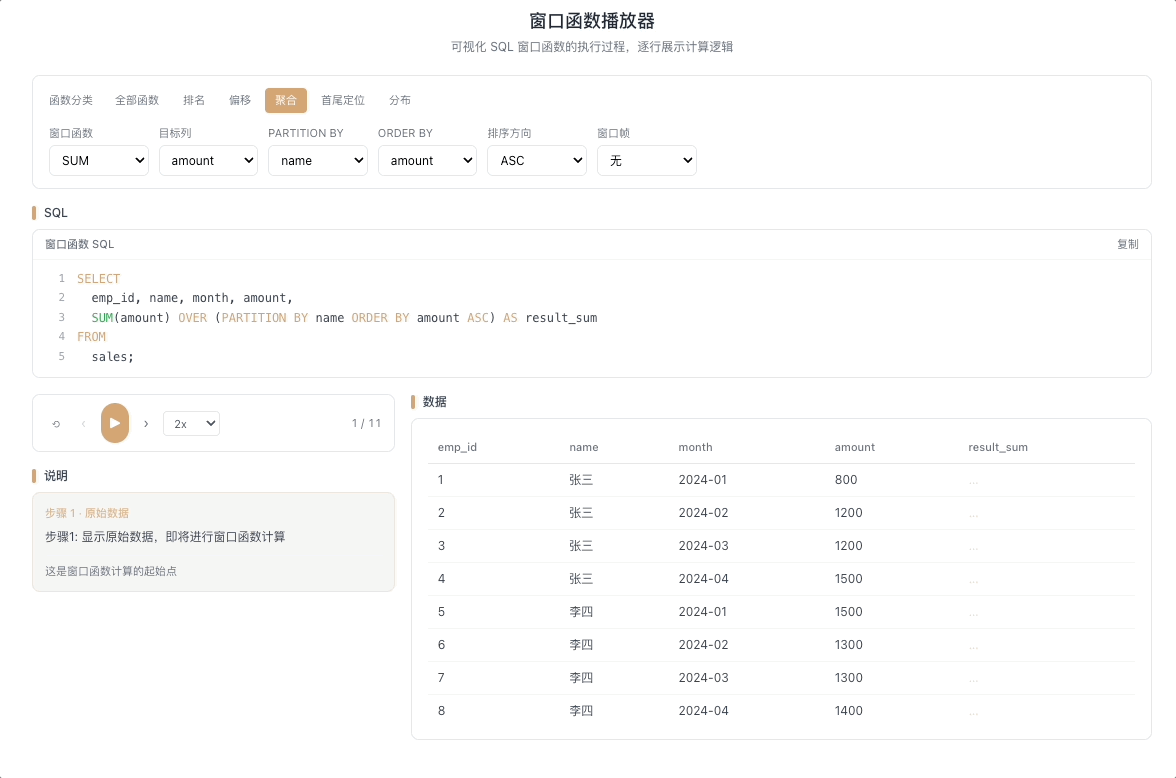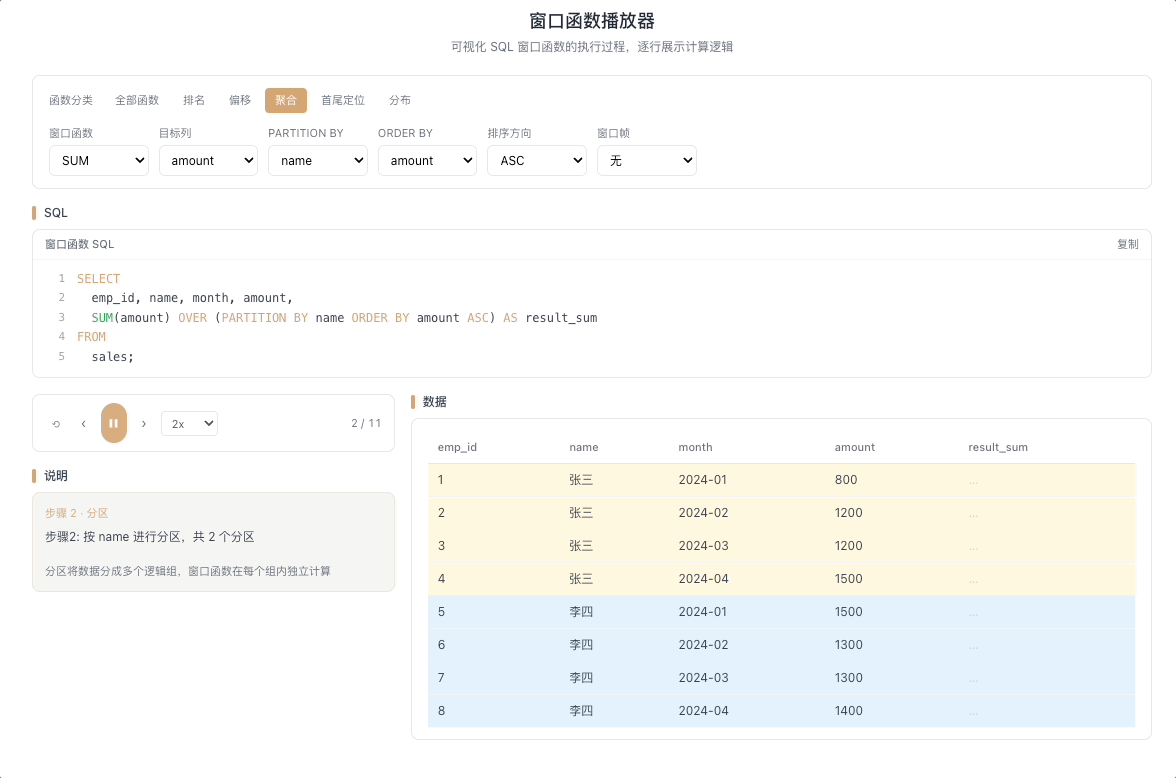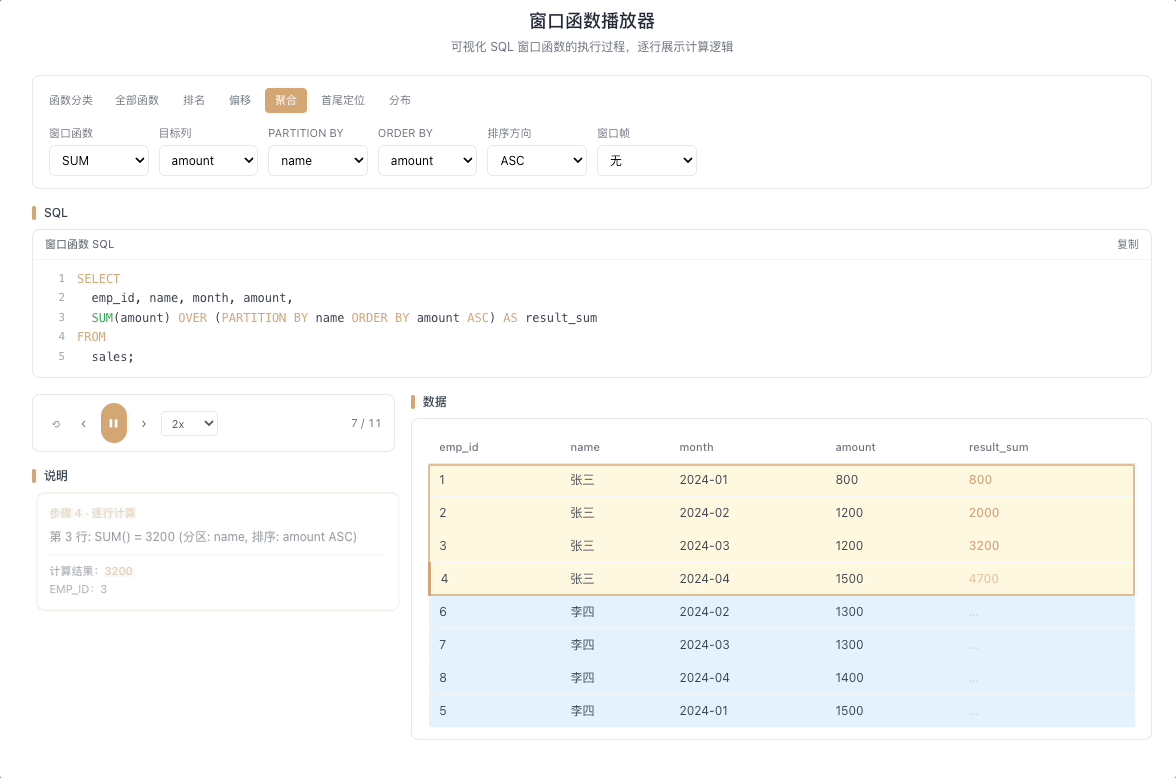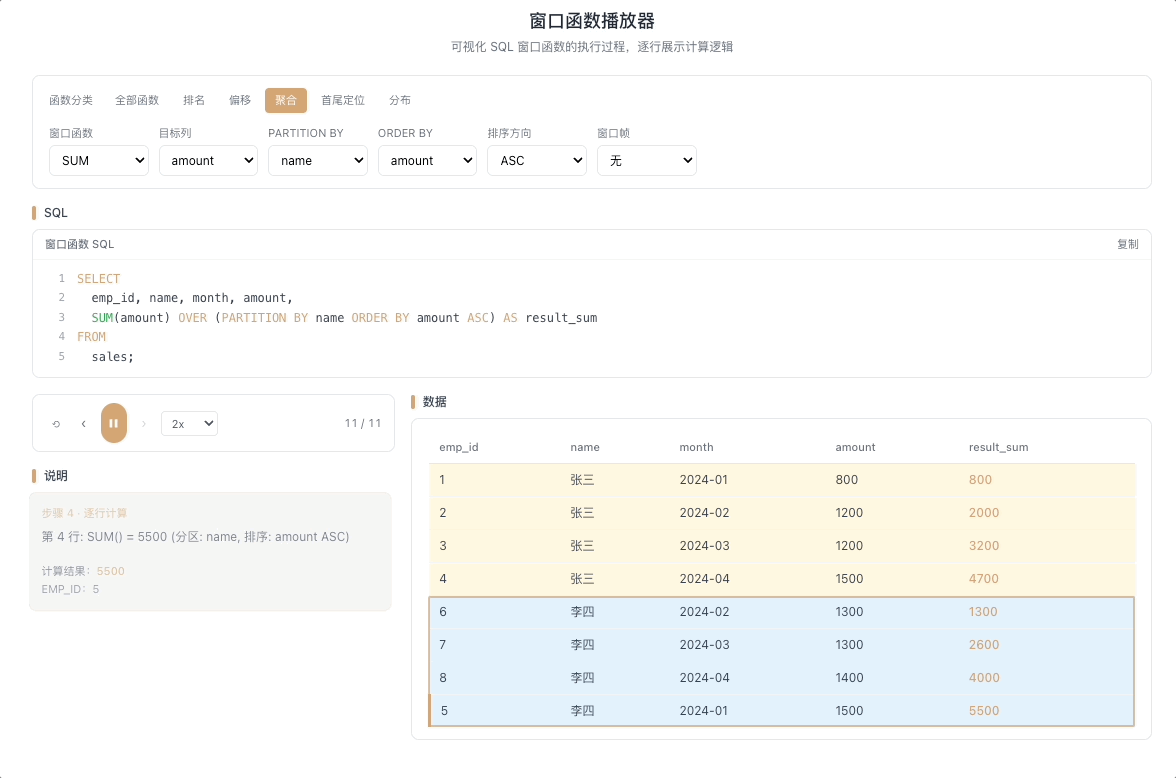
视觉焦点:随着当前行向下移动,上方所有格子的数值被动态累加,雪球越滚越大,最终汇聚成一个不断增长的总和。
销售额累计曲线、最近 N 天流水汇总的核心工具。 [→ 详解教程]
3.2 AVG OVER — 移动平均
AVG() OVER(...) 在窗口帧范围内计算平均值。移动平均是它最经典的应用——掐头去尾、平滑波动,让趋势浮出水面。
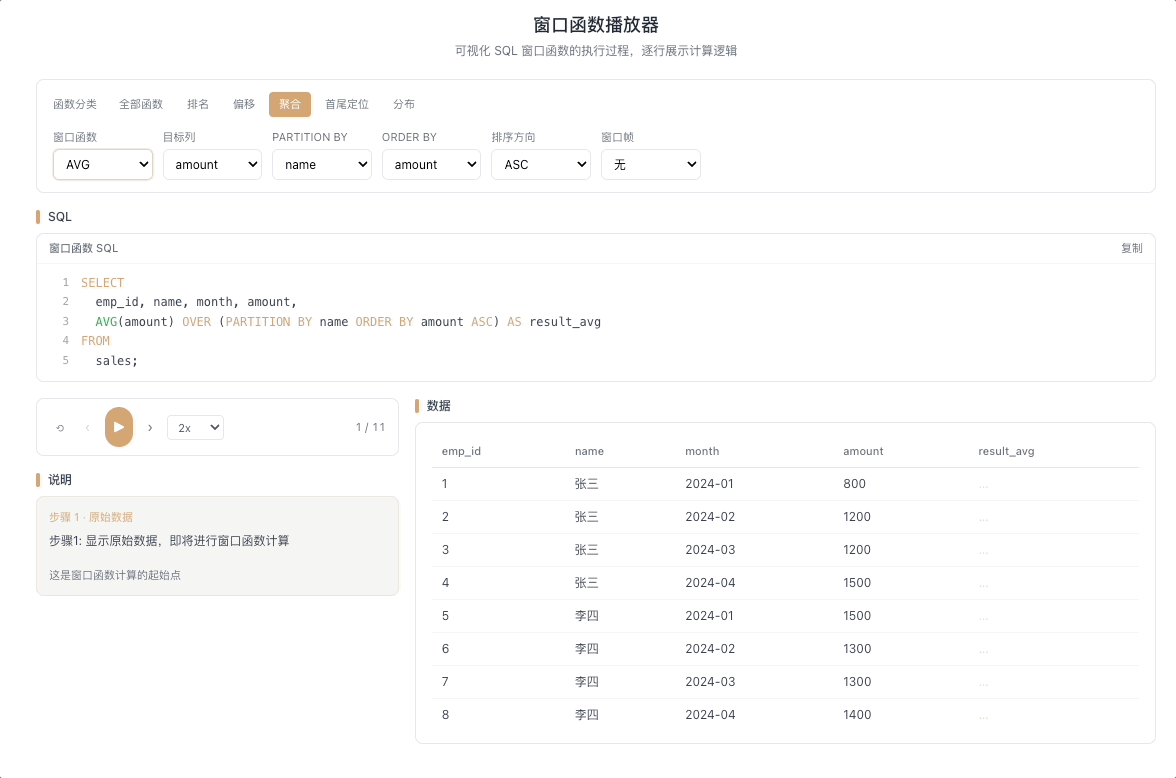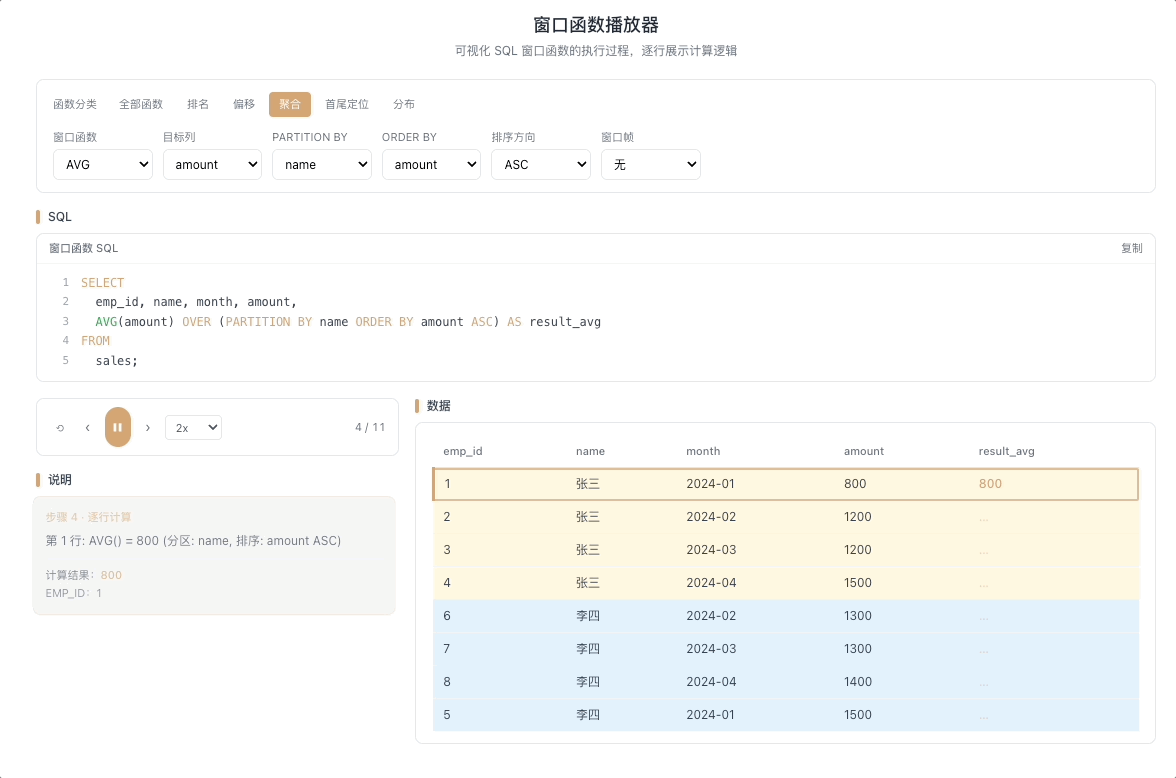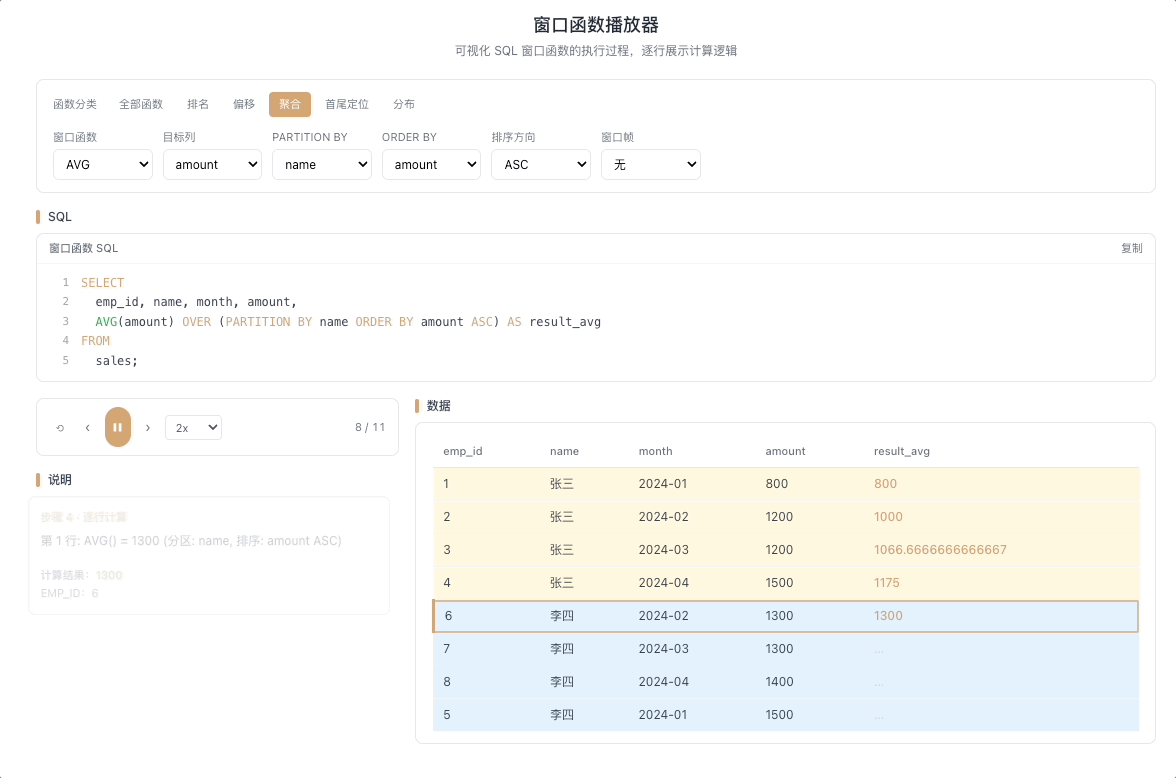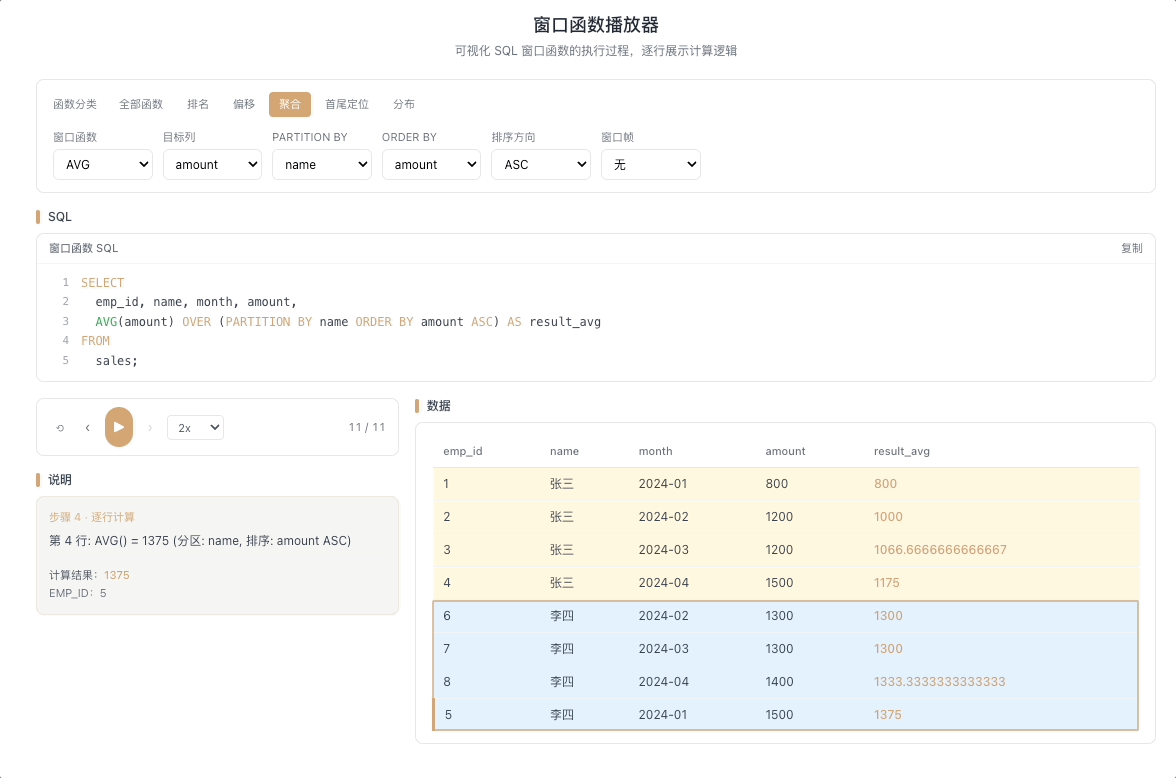
视觉焦点:一个半透明的滑动方框覆盖在数据列上,框内所有数值被实时求平均,框随当前行移动,平均值逐行刷新。
K 线均线计算、用户行为趋势分析、时间序列平滑的标配。 [→ 详解教程]
3.3 COUNT OVER — 累计计数
COUNT() OVER(...) 统计窗口帧内的行数。从第一行开始逐行累加计数,也可以配合窗口帧实现滑动窗口内的事件计数。
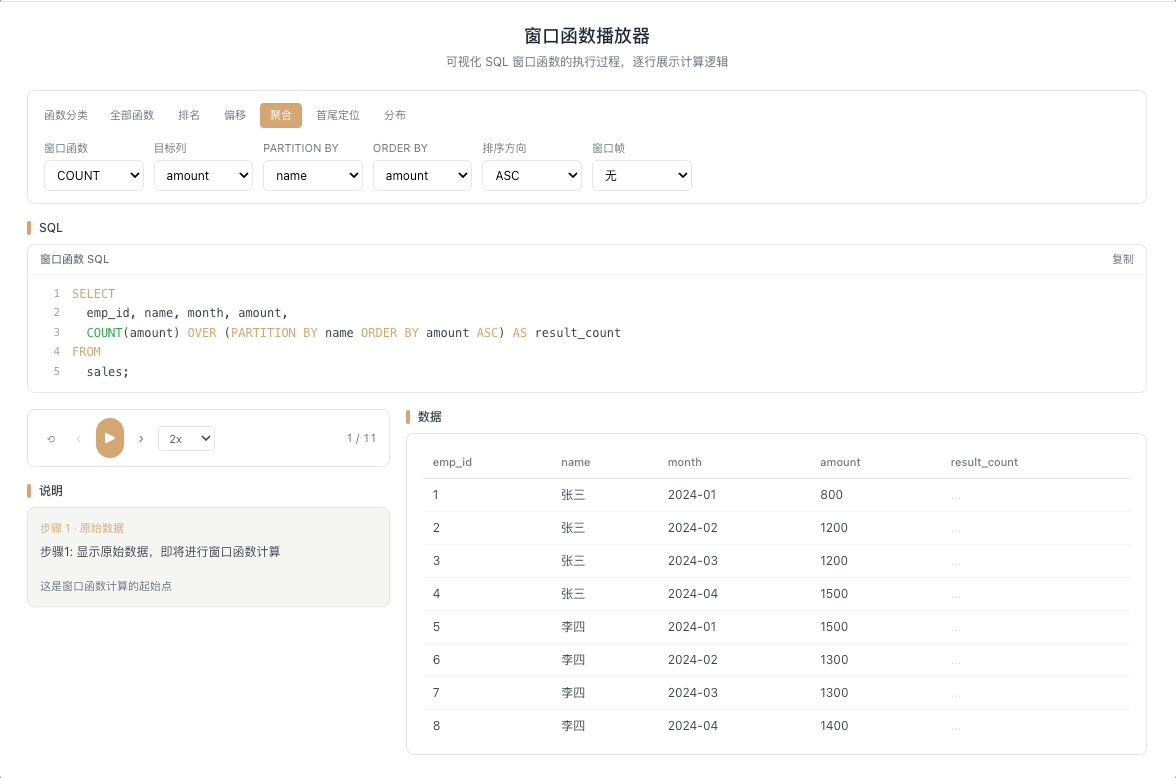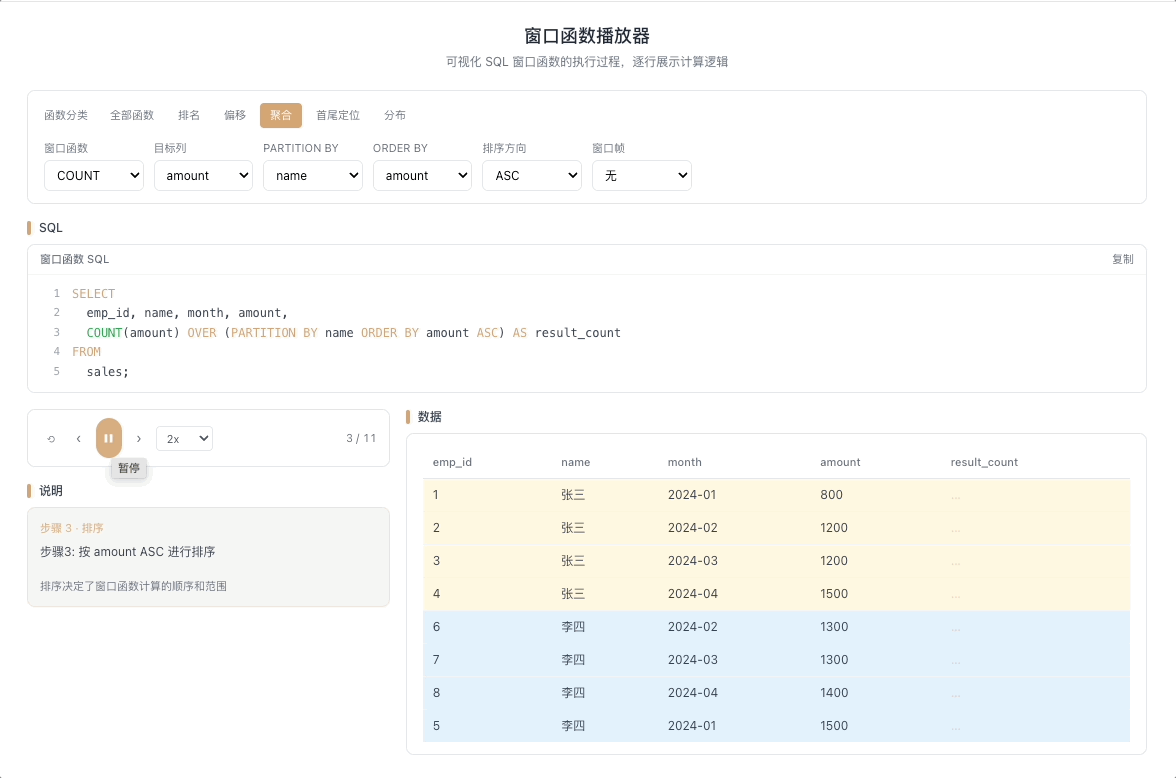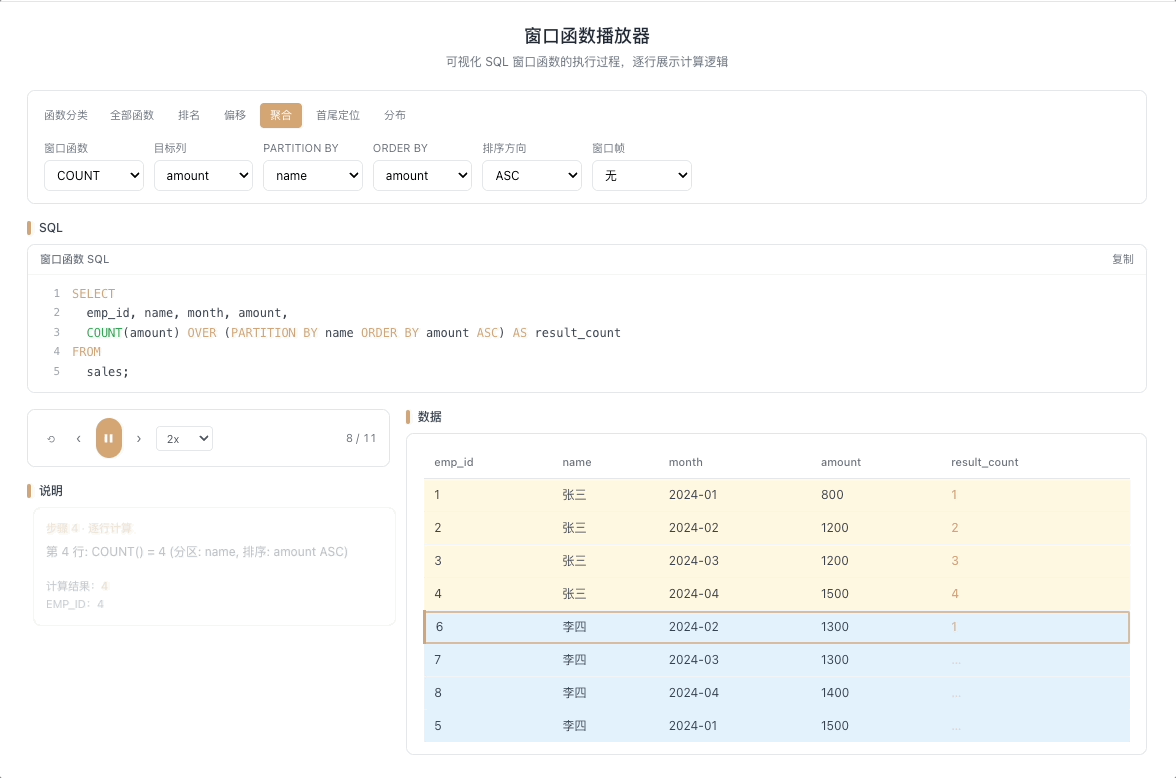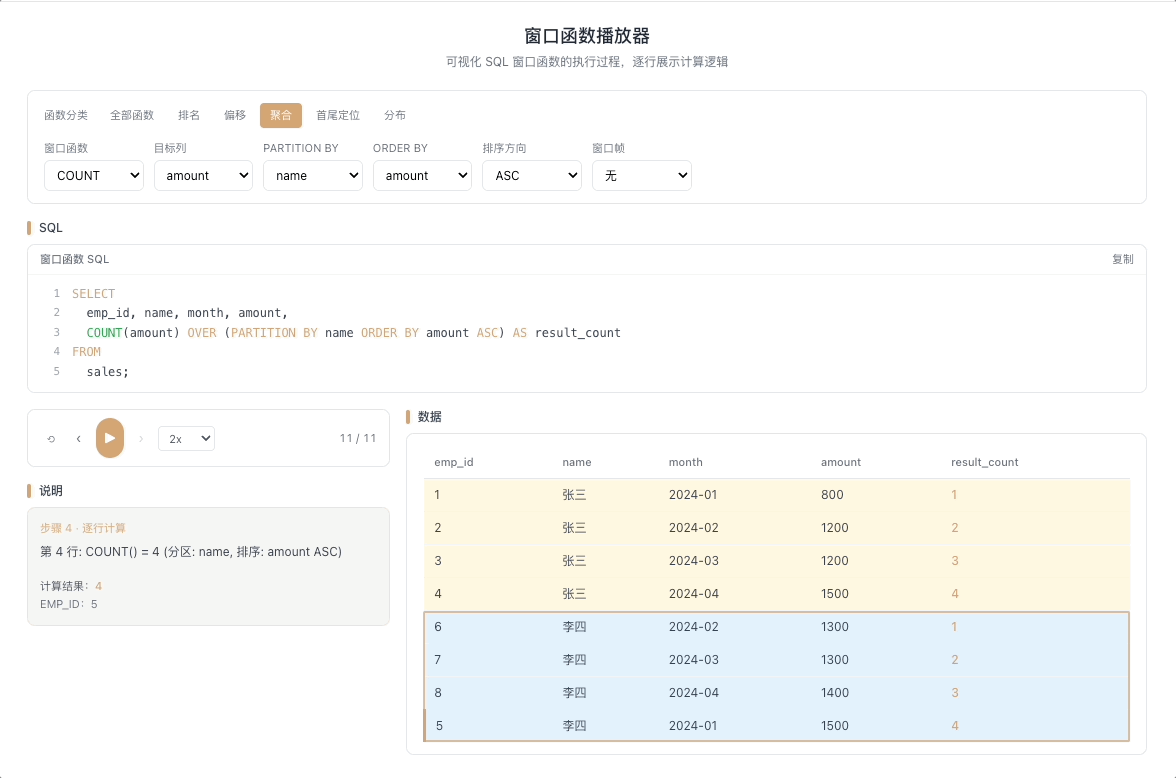
视觉焦点:计数器随着行推进逐行闪烁,每扫过一行就累加一次——注意观察它是统计"非空行数"而非"所有行数"。
用户行为漏斗各环节计数、滑动窗口内活跃天数统计。 [→ 详解教程]
3.4 MAX / MIN OVER — 窗口内极值
MAX() OVER(...) 和 MIN() OVER(...) 分别返回窗口帧内的最大值和最小值。最经典的用法是计算截至当前行的历史极值——只有当新行打破历史纪录时,输出值才会发生变化。
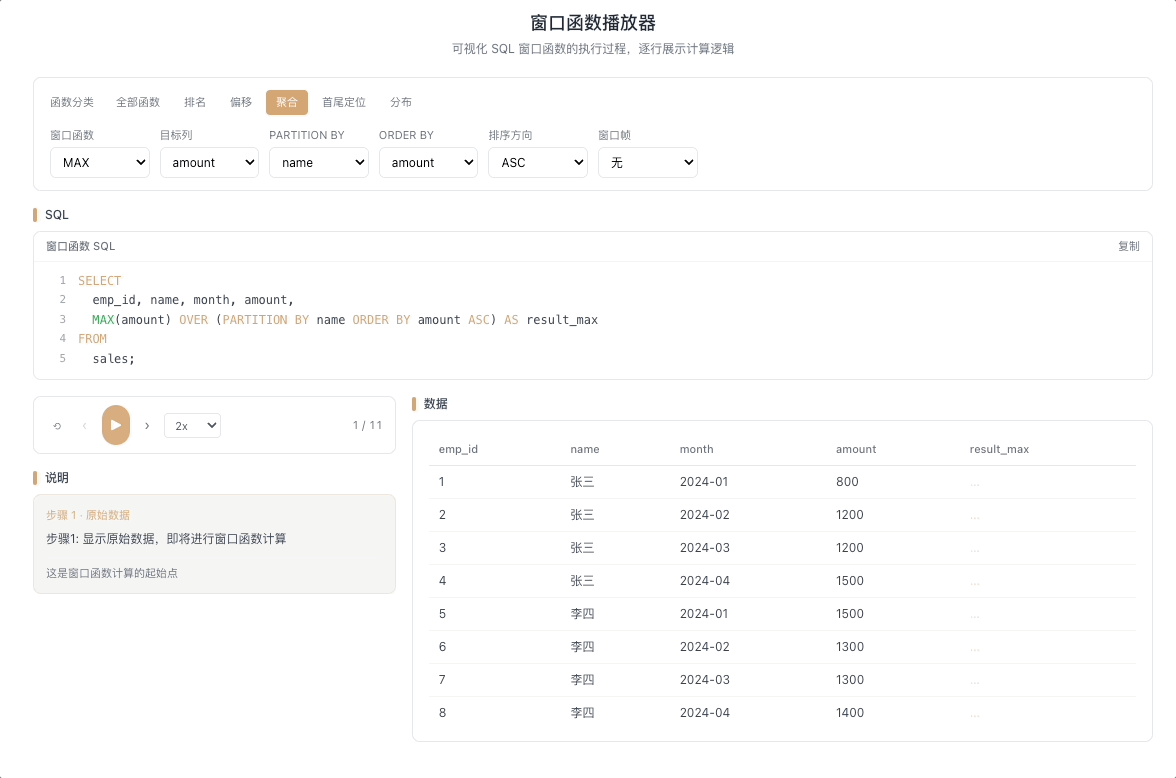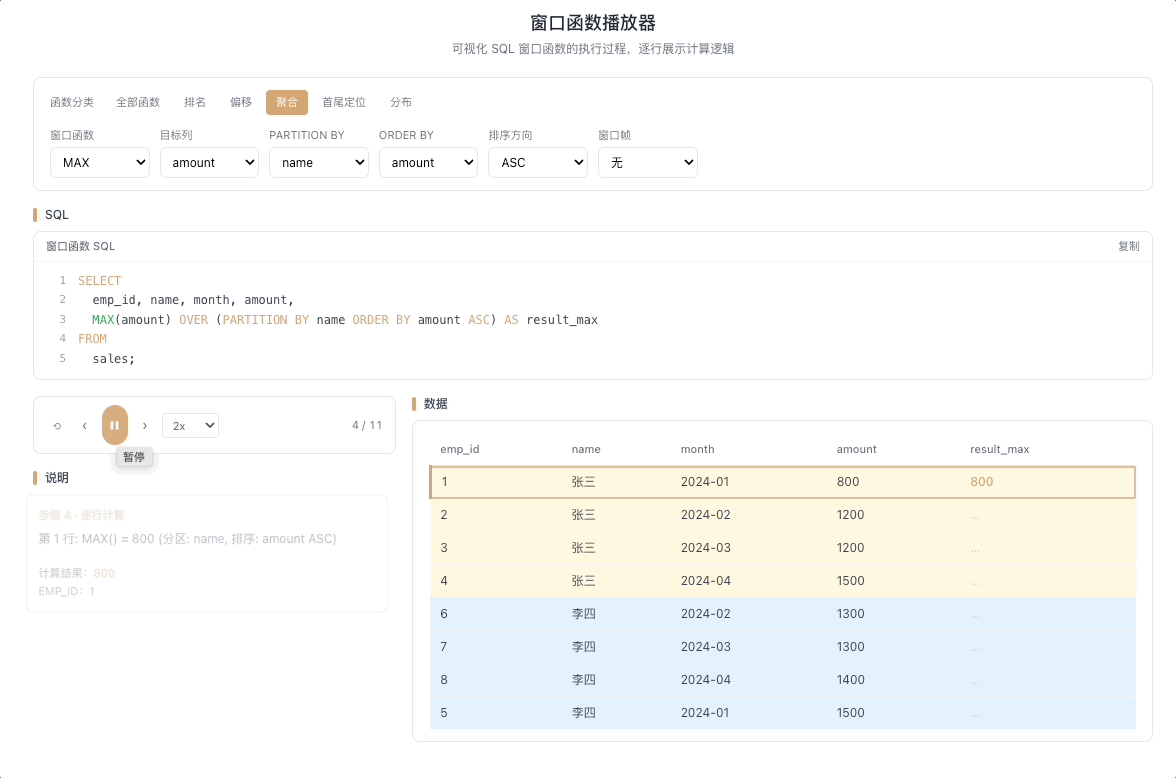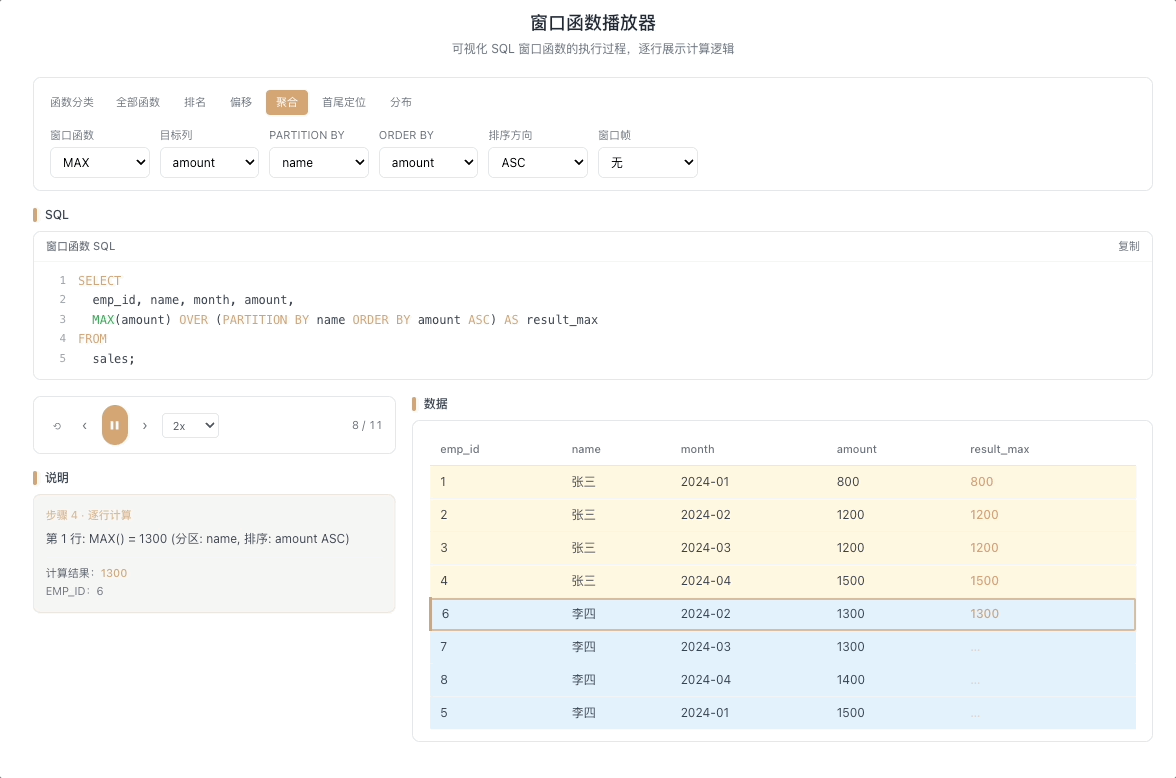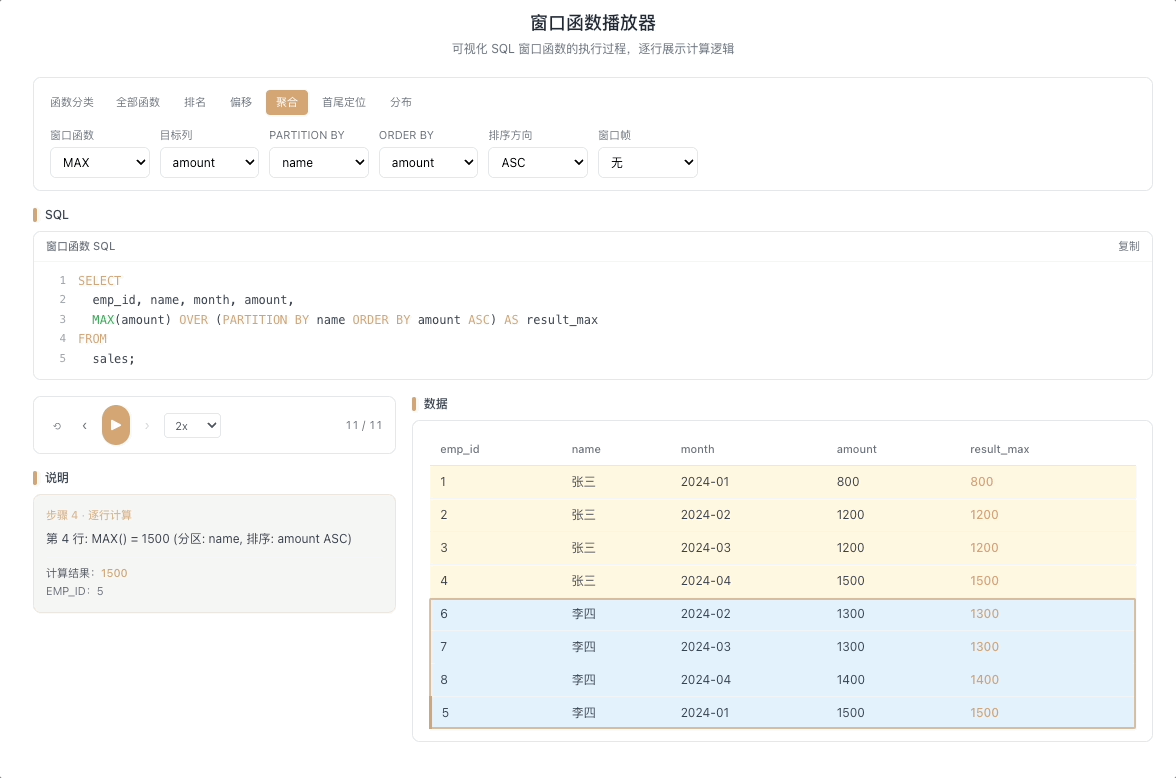
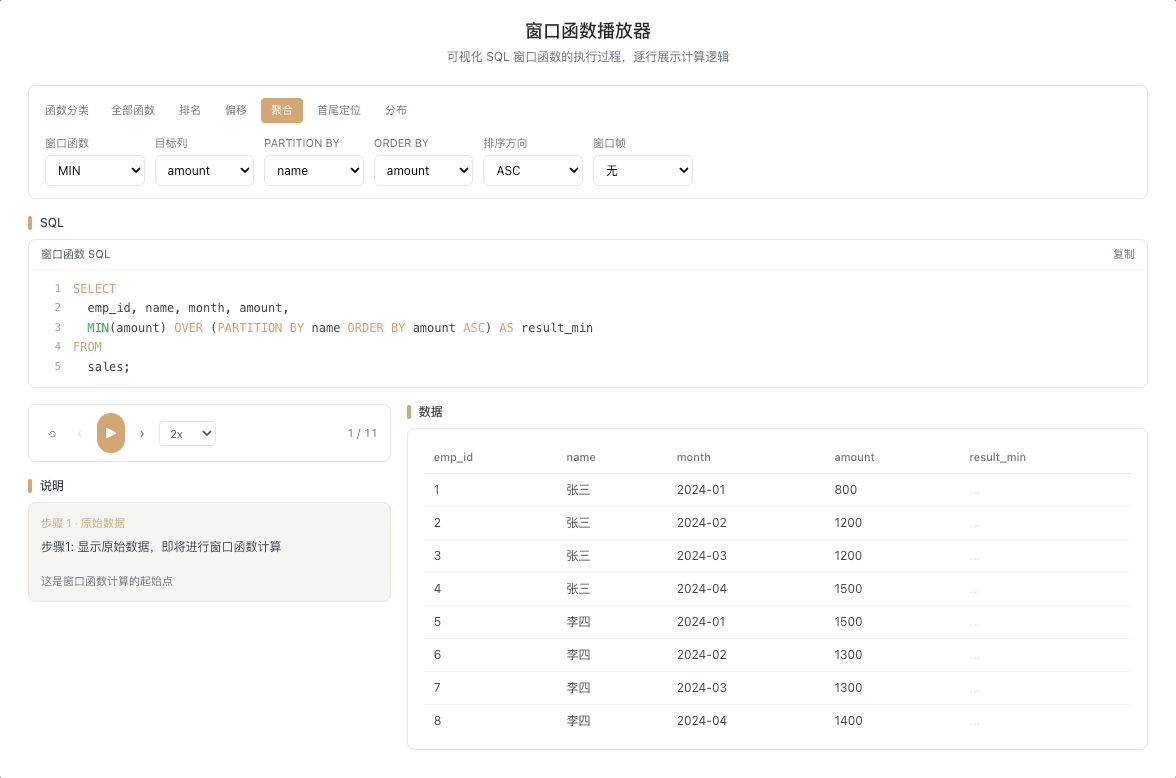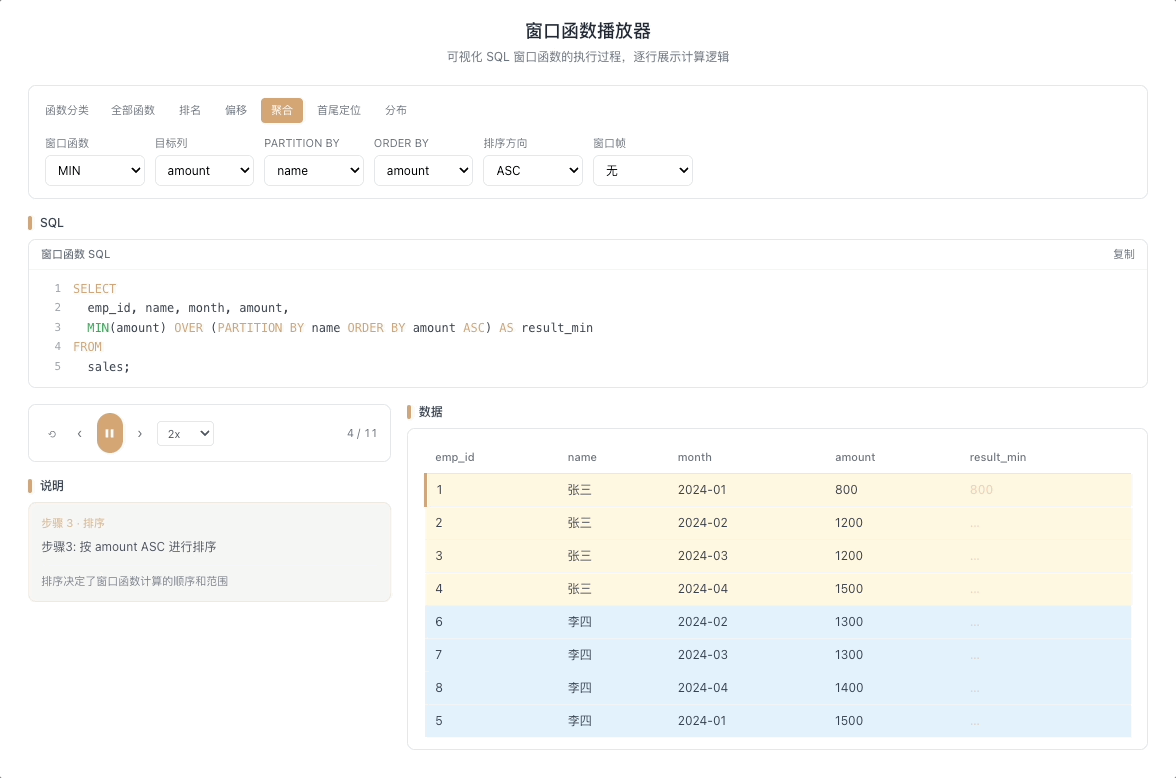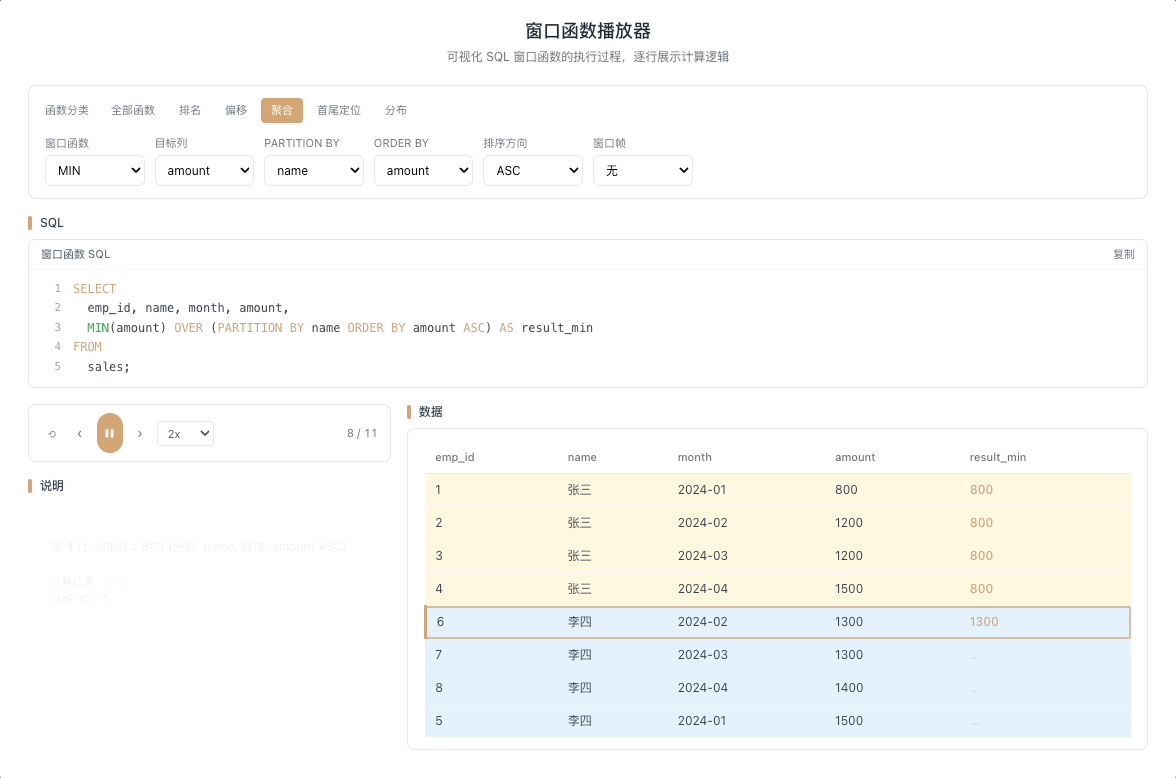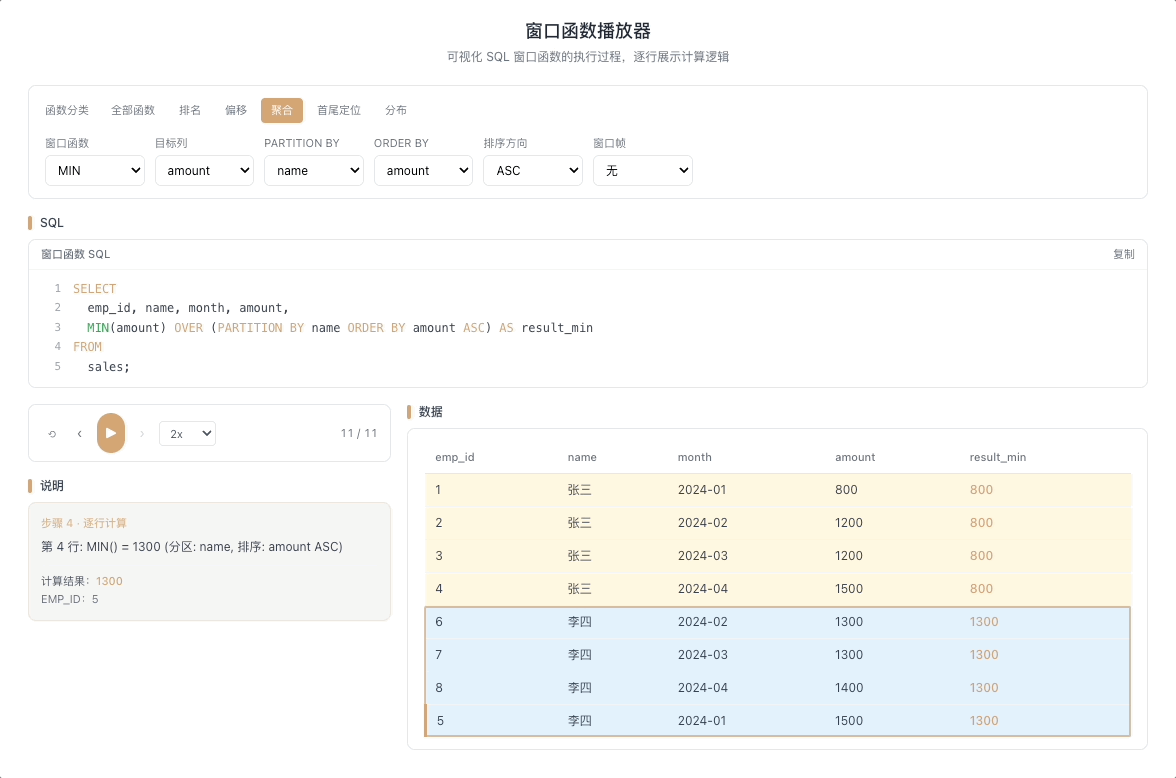
视觉焦点:注意聚合输出值并不是每行都变——只有当光标扫过的新数据打破了历史最高(或最低)纪录时,输出值才出现"台阶式跳跃"。
股价历史最高/最低、用户消费峰值记录、设备温度极值监控等场景。 [→ 详解教程]
四、首尾定位函数
首尾定位函数专注于取窗口内特定位置的值——第一行、最后一行、第 N 行。它们与偏移函数(LAG/LEAD)有本质区别:不看"距离当前行几行",只看"在窗口中的绝对位置"。它们是窗口内的锚点、追踪器和精准指针。
4.1 FIRST_VALUE — 窗口首行的值
FIRST_VALUE(expr) 返回窗口帧内第一行的 expr 值。它像一个锁定不动的锚点——无论窗口帧如何随当前行滑动变化,始终牢牢钉在帧的起点位置。
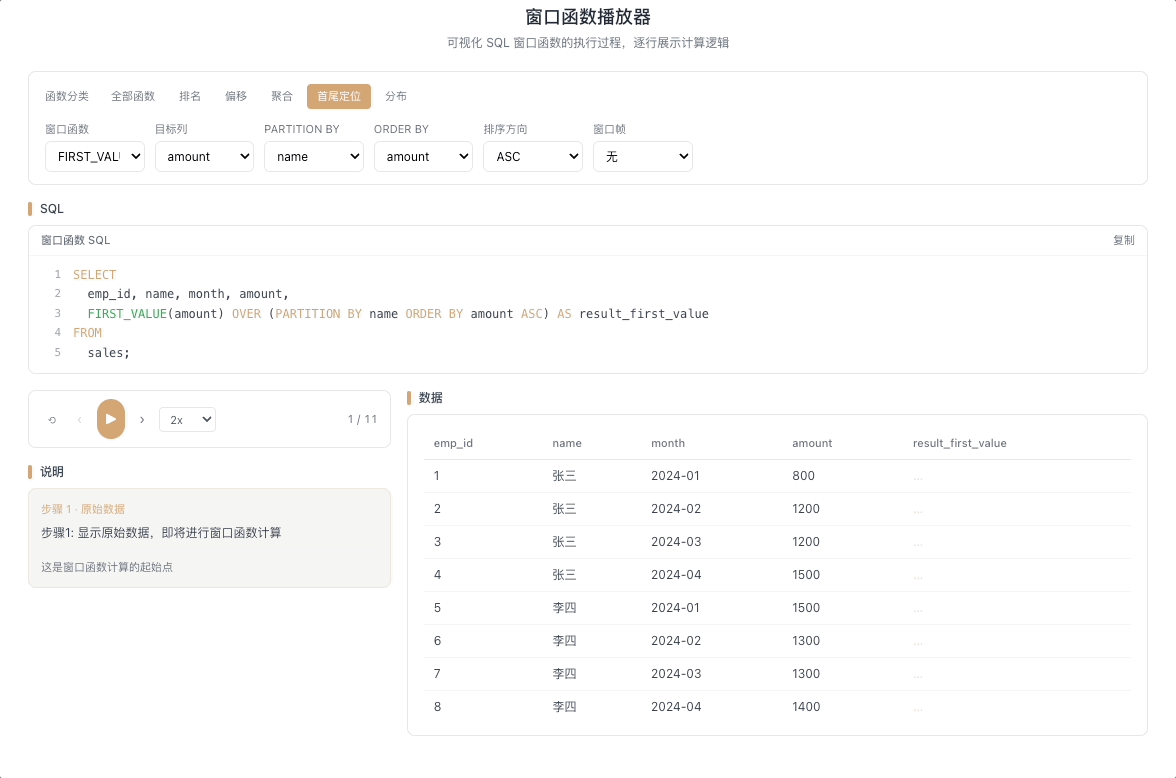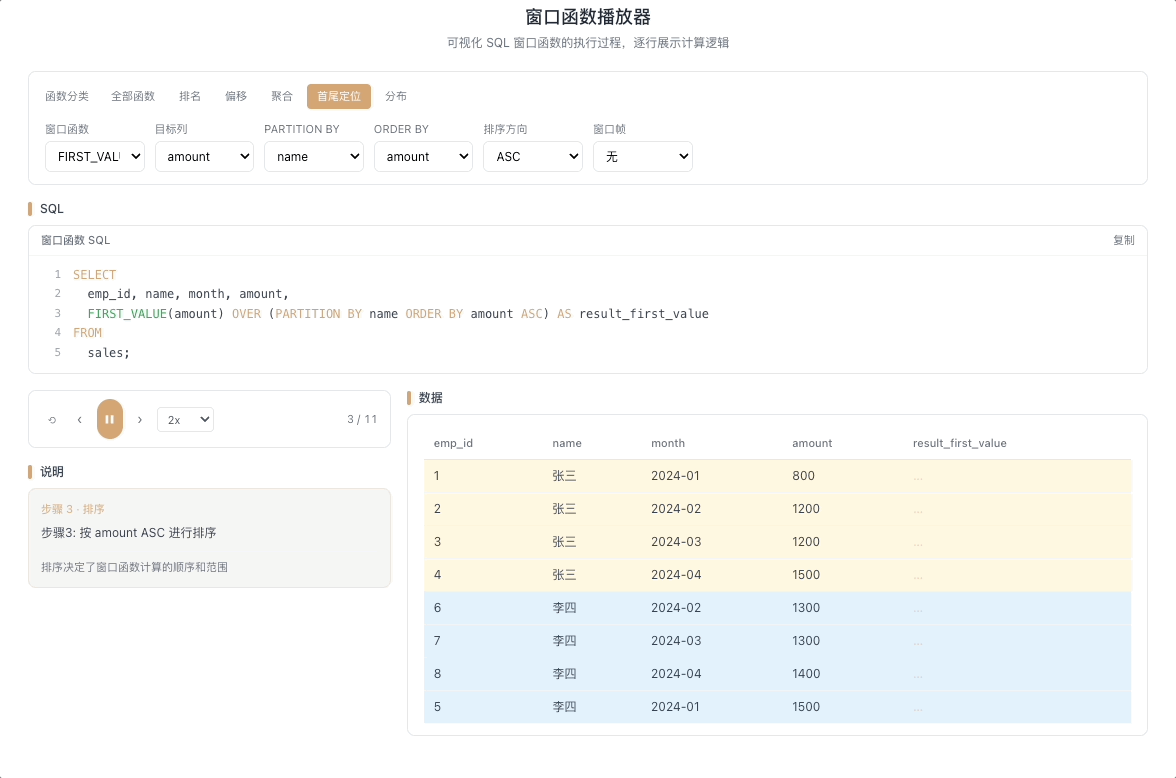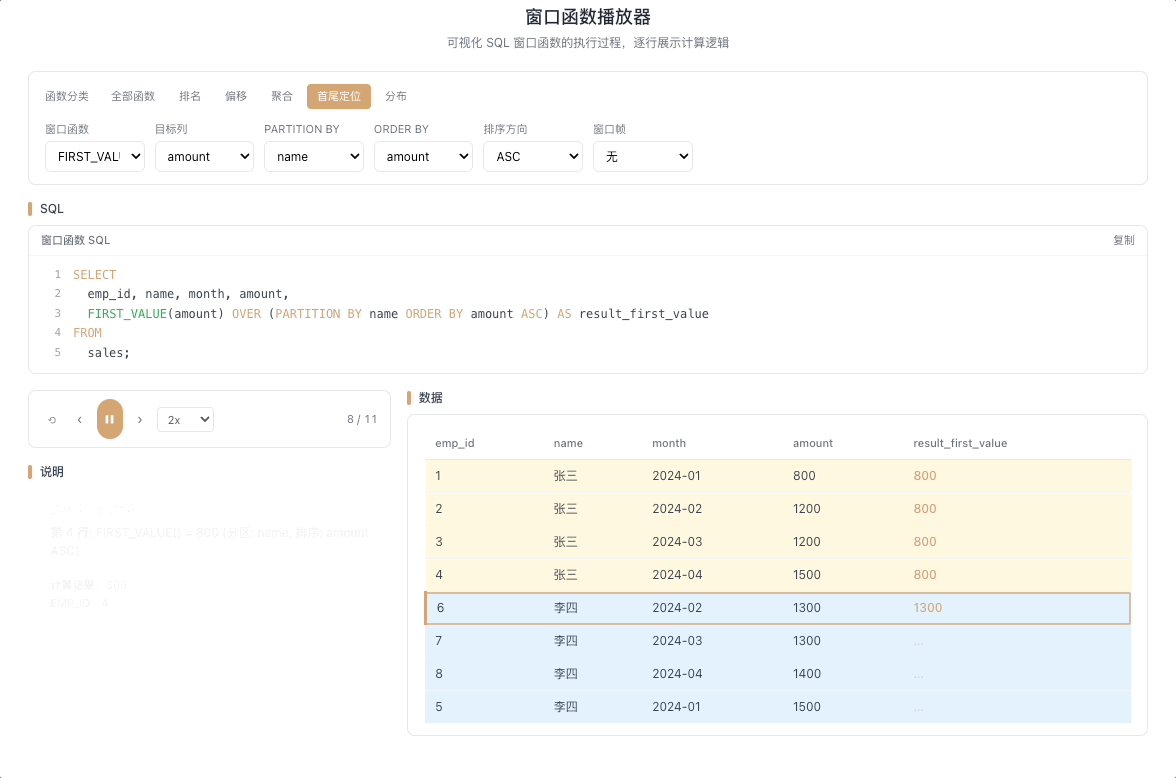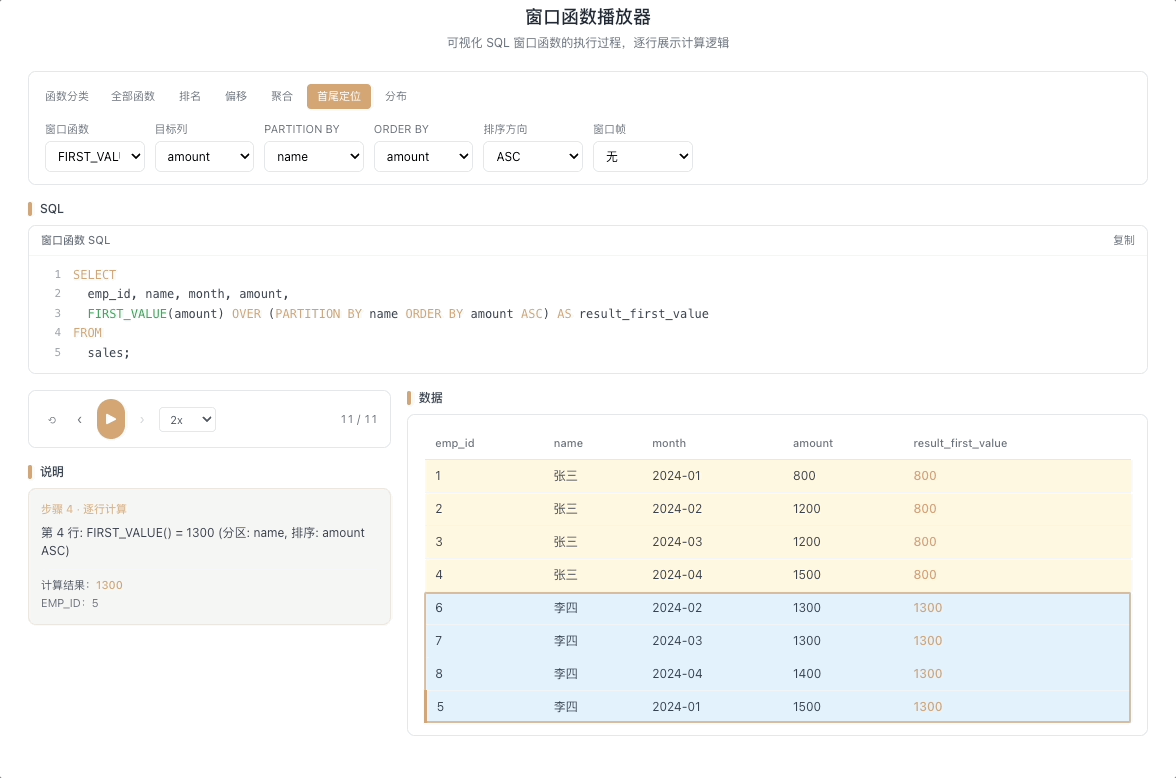
视觉焦点:窗口的第一行被高亮锁定,其数值被不断广播到当前行所在列的每一个格子里,像固定的参照线。
查询每个用户的首单金额、首次登录时间、以首日为基准计算每日偏离度。 [→ 详解教程]
4.2 LAST_VALUE — 窗口末行的值
LAST_VALUE(expr) 返回窗口帧内最后一行的 expr 值。这里有一个最容易踩的坑:默认窗口帧是 RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW,这意味着在不指定窗口帧的情况下,LAST_VALUE 永远只会取到当前行本身,而不是分区的最后一行。
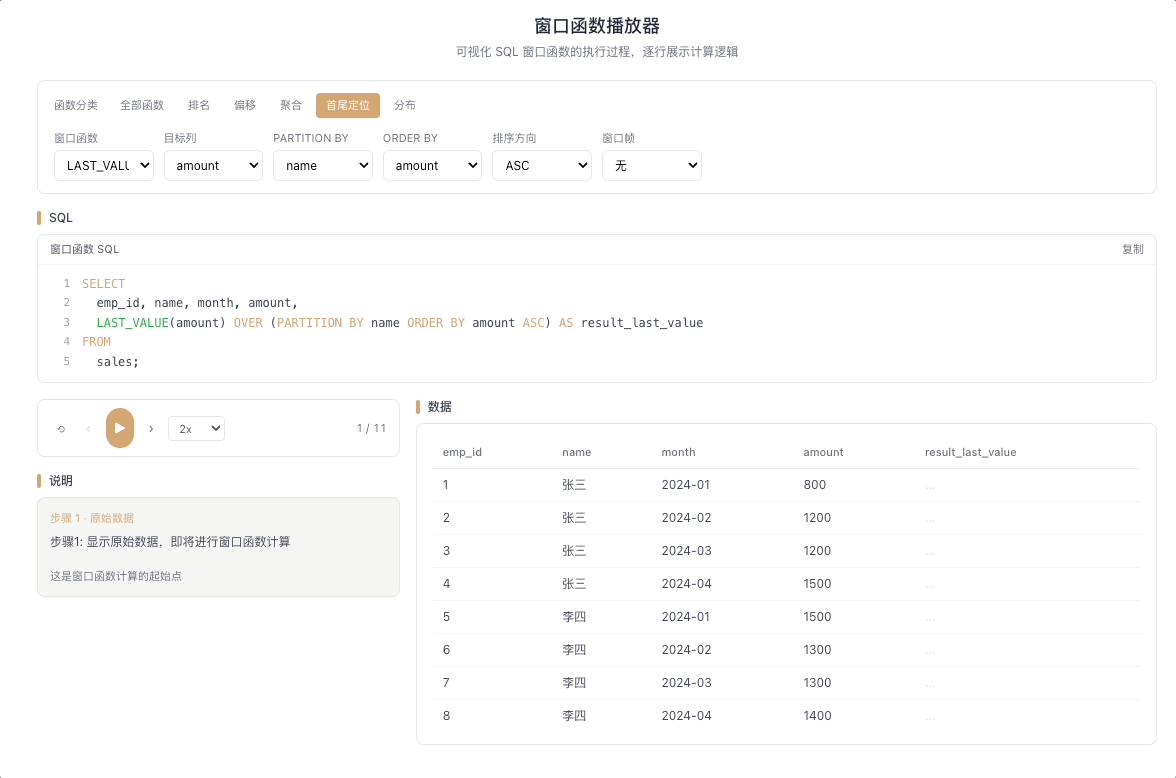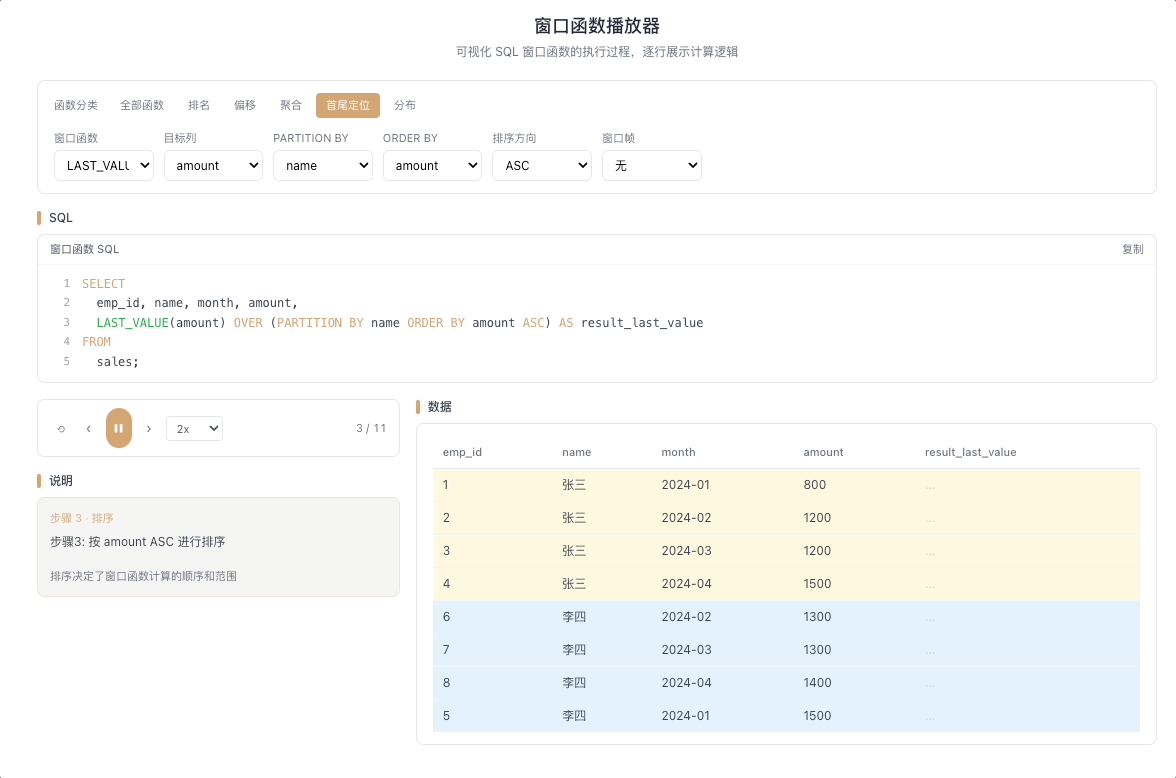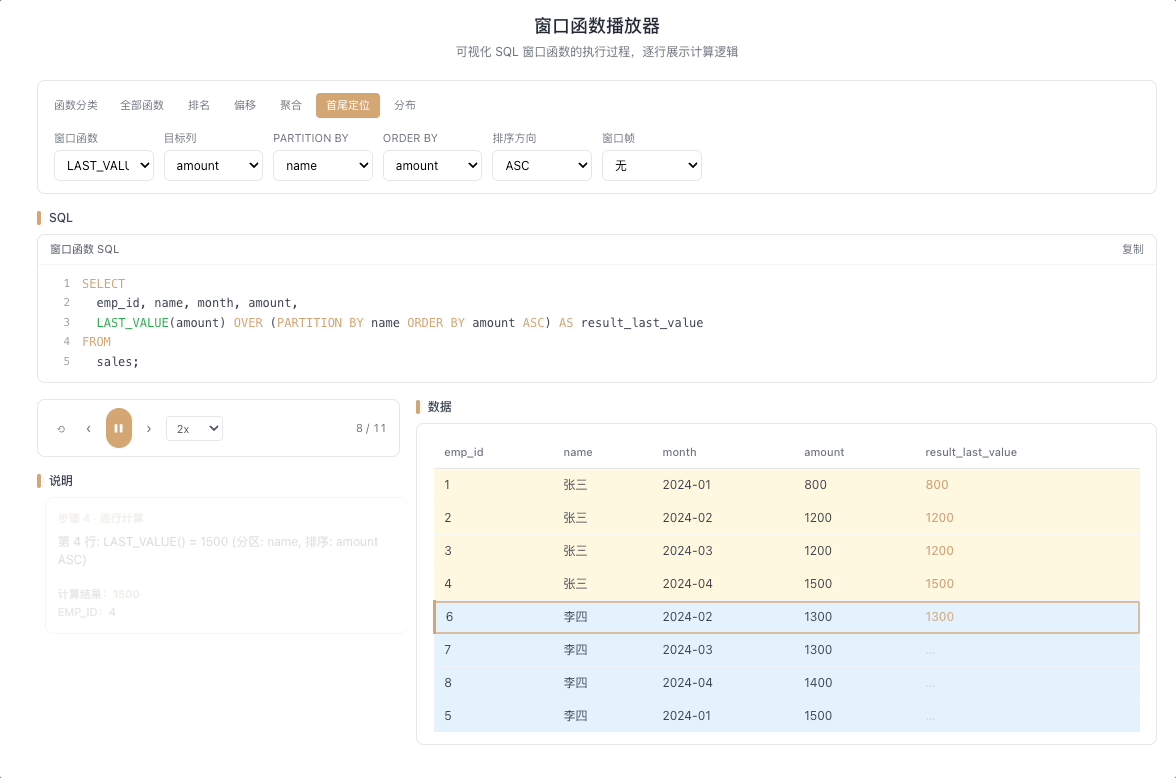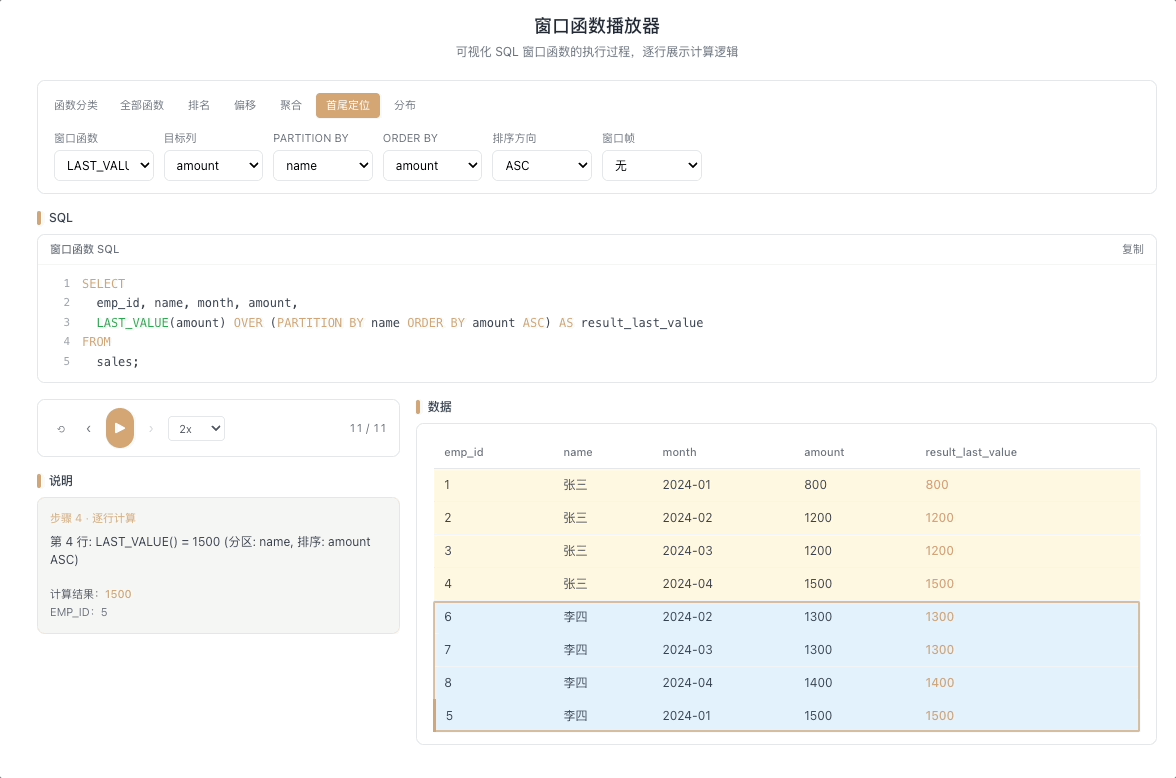
视觉焦点:仔细观察——如果不加
ROWS BETWEEN ...,LAST_VALUE 的值会和当前行的原始值完全一致;只有当窗口帧被正确设定为延伸到分区末尾时,它才会真正取到末行数据。
使用
ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING才能让它名副其实。 [→ 详解教程]
4.3 NTH_VALUE — 窗口第 N 行的值
NTH_VALUE(expr, N) 返回窗口帧内第 N 行的 expr 值。比 FIRST_VALUE / LAST_VALUE 更灵活——你可以在窗口中任意指定一个精确位置,想取第几行就取第几行。
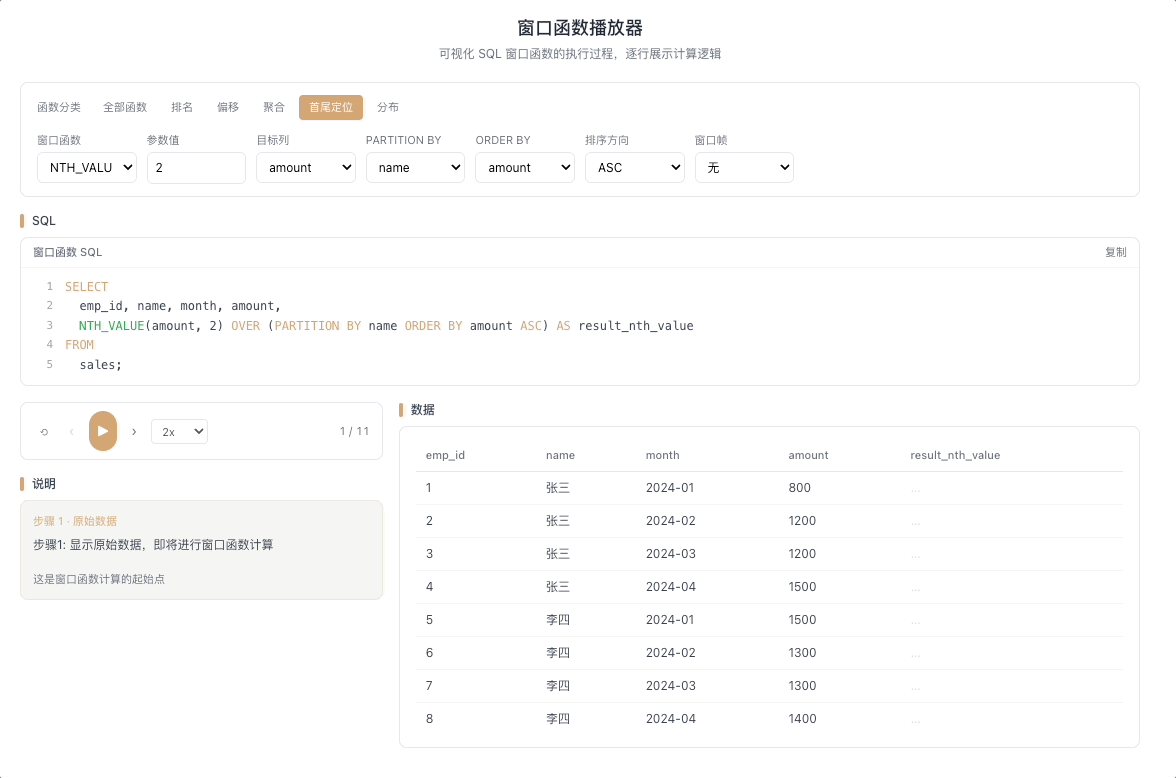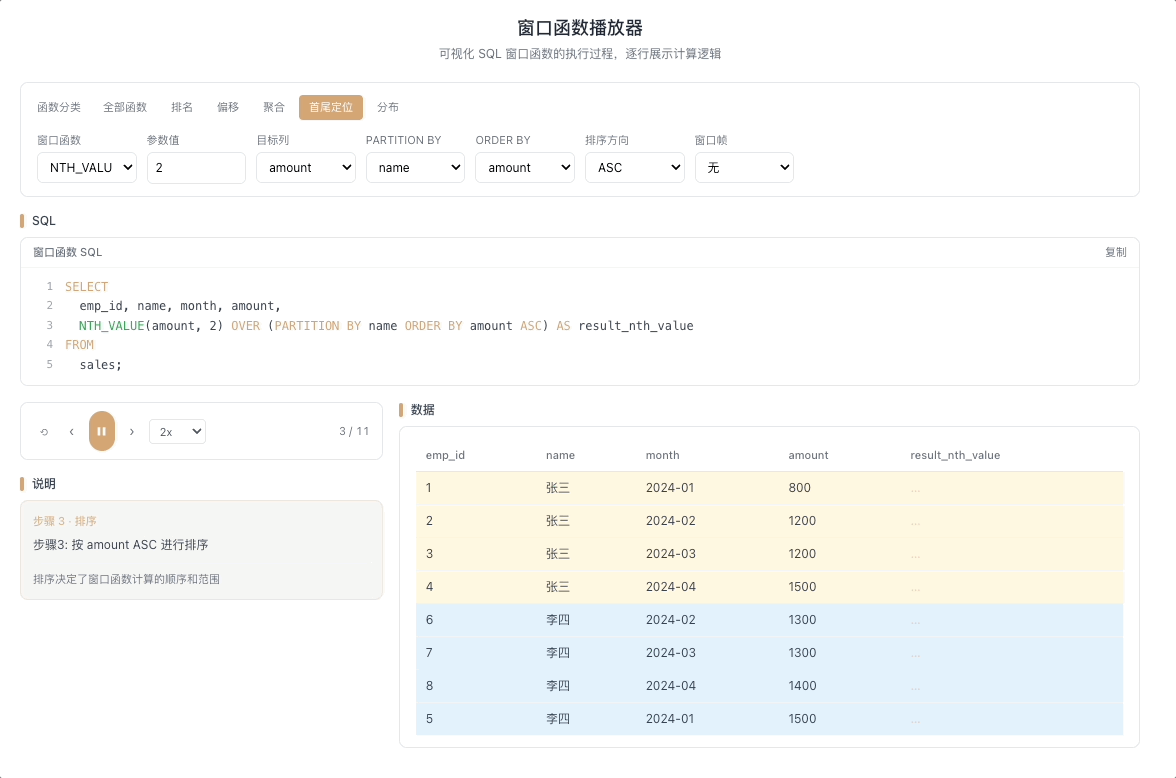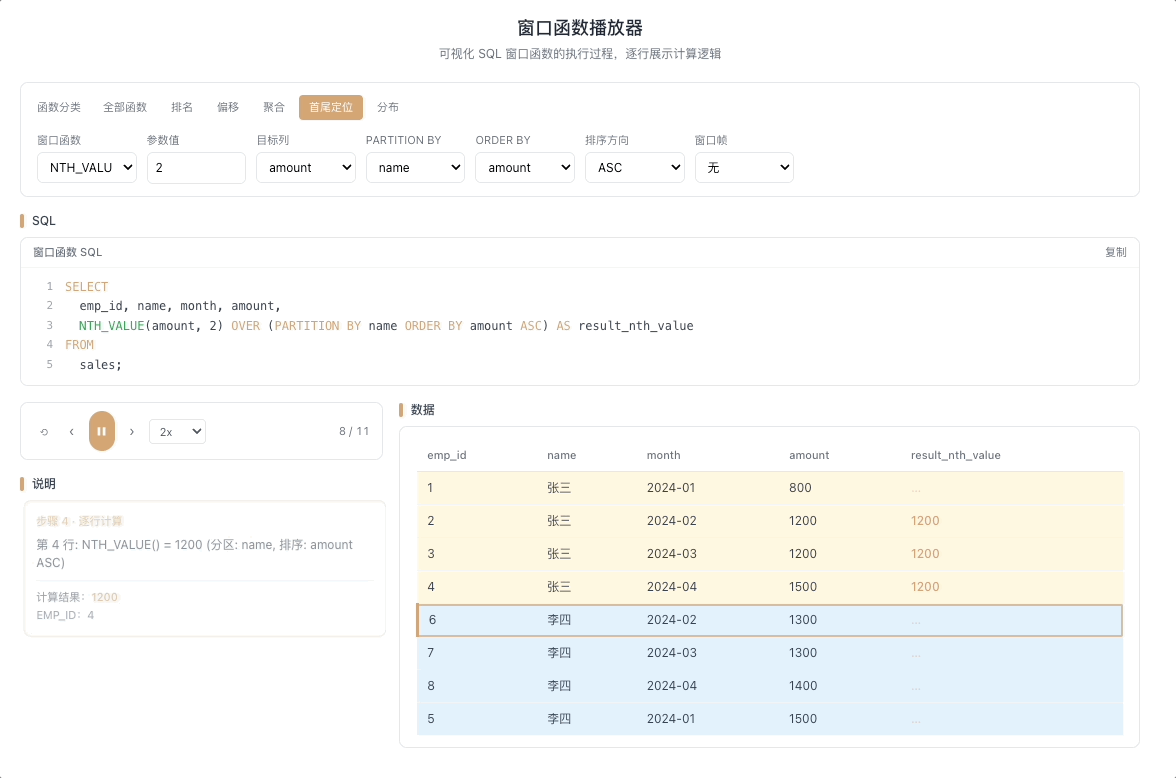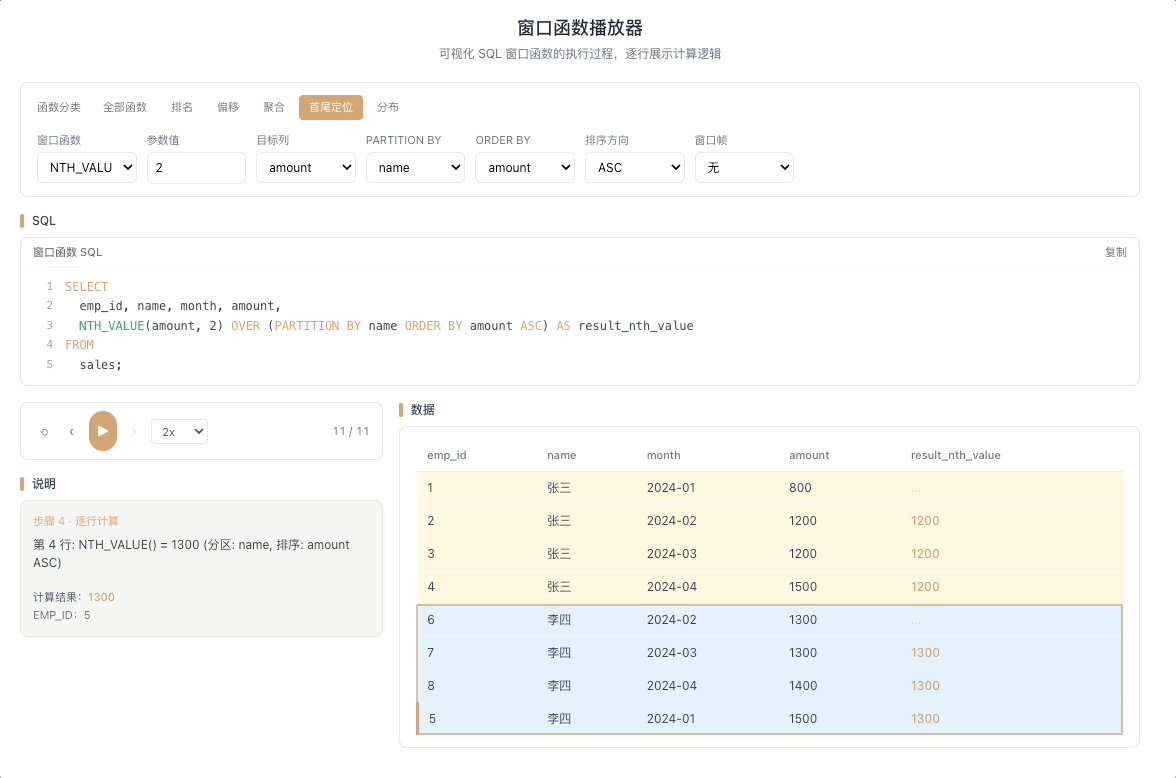
视觉焦点:定位指针死死指向窗口内的第 N 个格子,无论窗口怎么滑动,它永远抽取那个固定位置的值。
取分组内第 N 条记录、第 N 高的值——在分区内按序精准取值的利器。 [→ 详解教程]
五、分布函数
分布函数不关心具体的数据值是多少,只关心当前行在排序后的分区中"排第几"以及"覆盖了多少比例"。返回值始终在 0 到 1 之间,对数据规模不敏感,适合跨组比较。
5.1 CUME_DIST — 累积分布
CUME_DIST() 计算值小于等于当前行的行数占总行数的比例。返回值范围 (0, 1]。
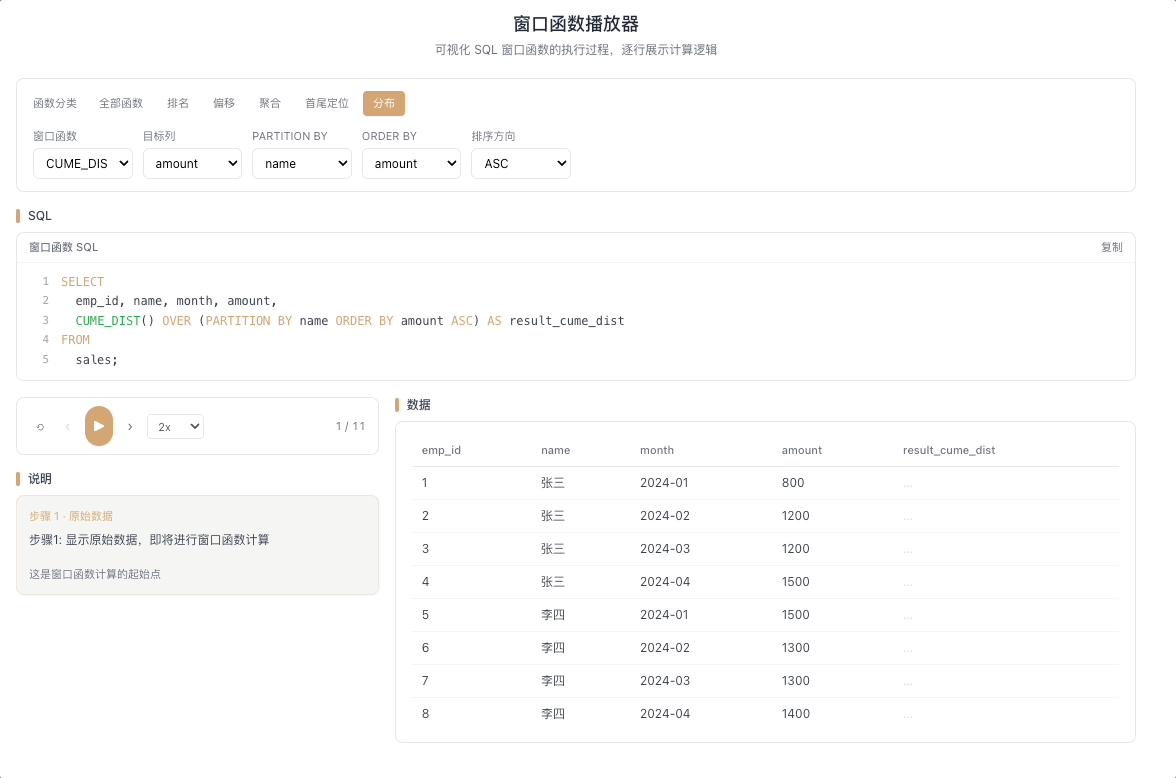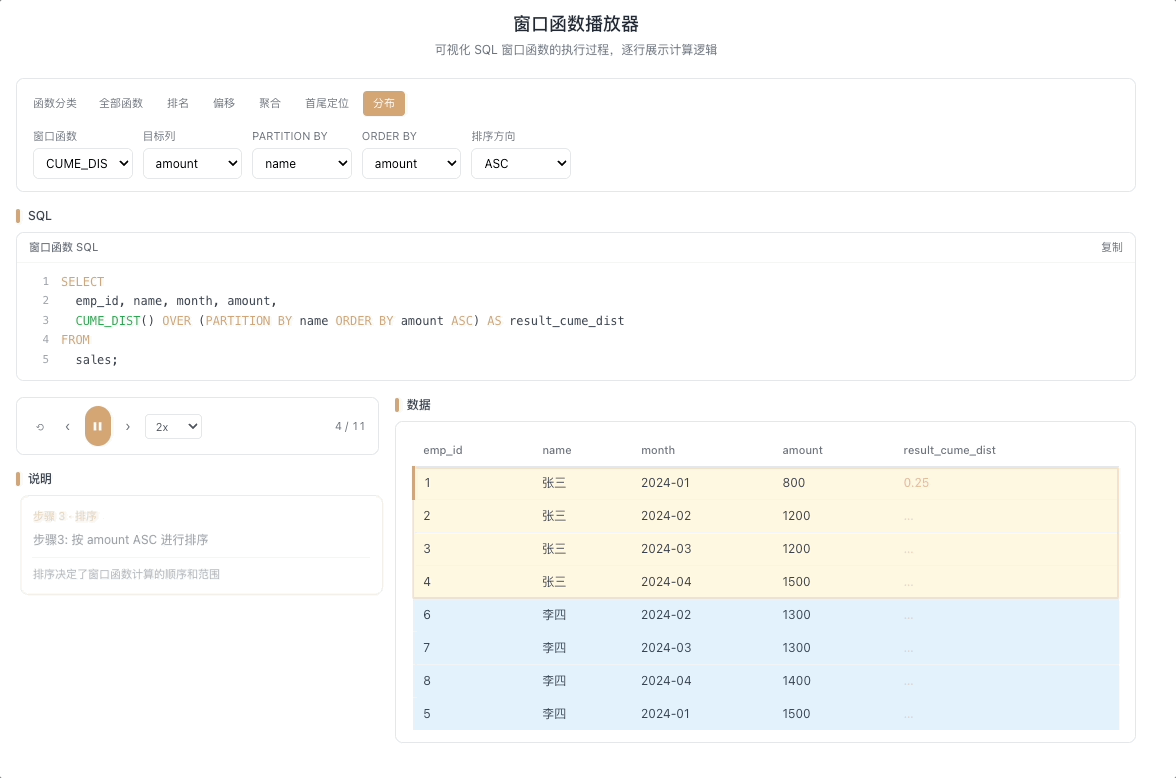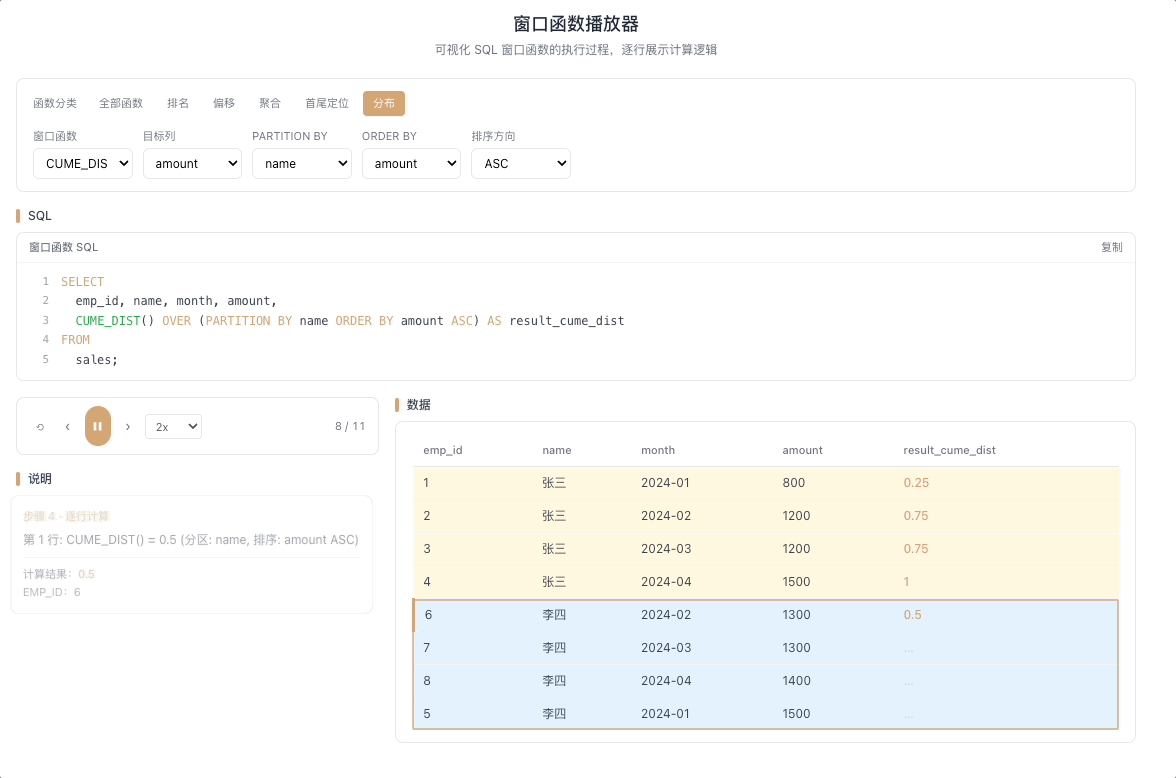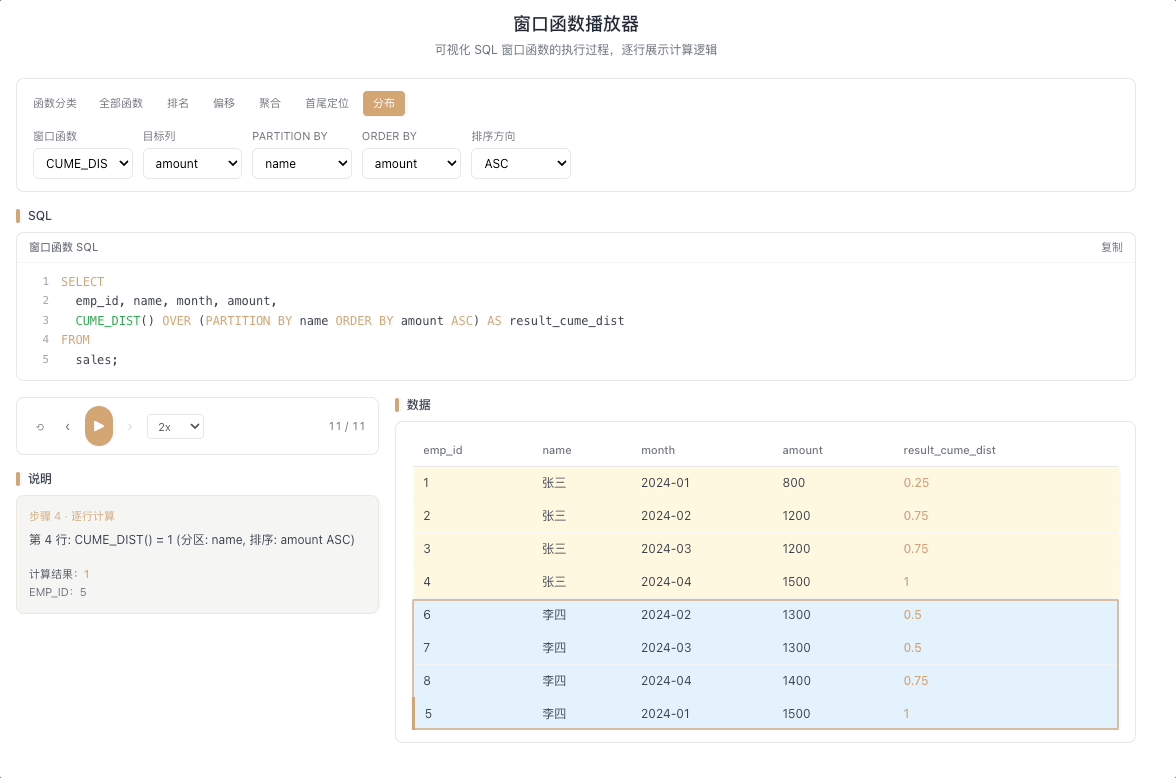
视觉焦点:随着光标逐行向下扫描,累积比例从接近 0 开始逐步攀升,直到最后一行稳稳落在 1.0——关注比例值增长的节奏变化。
全班 50 人,CUME_DIST = 0.8 意味着"你的成绩排在前 80%(超过了全班 80% 的人)"。 [→ 详解教程]
5.2 PERCENT_RANK — 百分比排名
PERCENT_RANK() 计算公式为 (rank - 1) / (total_rows - 1),返回值范围 [0, 1]。第一行永远是 0,最后一行永远是 1,中间各行按排名位置线性分布。
![]()
视觉焦点:第一行输出始终为 0,最后一行始终为 1,中间比例随排名线性渐变——观察这个梯度是否均匀,能判断数据分布的疏密。
与 CUME_DIST 的核心区别:PERCENT_RANK 关注"排位相对位置",CUME_DIST 关注"值覆盖比例"。 [→ 详解教程]
避坑指南:窗口函数的执行顺序
窗口函数虽然强大,但有一个铁律必须牢记——下面的 SQL 执行顺序决定了你能在哪使用它:
FROM → WHERE → GROUP BY → HAVING → 窗口函数 (OVER) → SELECT → DISTINCT → ORDER BY → LIMIT
从这个顺序可以得出两个关键结论:
坑1:WHERE 里不能写窗口函数。 因为窗口函数在 WHERE 之后才执行,WHERE 子句根本看不到窗口函数的结果。如果需要按窗口函数的结果过滤,必须用子查询或 CTE 包裹一层:
-- 错误写法
SELECT * FROM t WHERE ROW_NUMBER() OVER(PARTITION BY dept ORDER BY salary) = 1
-- 正确写法:子查询包裹
SELECT * FROM (
SELECT *, ROW_NUMBER() OVER(PARTITION BY dept ORDER BY salary) AS rn FROM t
) tmp WHERE rn = 1
坑2:排序唯一性是数据质量的底线。 使用 ROW_NUMBER 取每组第一条时,如果 ORDER BY 的字段不能保证唯一排序,每次查询返回的结果可能不一样——流程重跑时数据对不上,排查极其困难。养成在 ORDER BY 末尾加唯一字段(如主键)的习惯,确保结果是可复现的。
十六算子对比速查表
| 分类 | 函数 | 决定因素 | 并列处理 | 典型场景 |
|---|---|---|---|---|
| 排名 | ROW_NUMBER | 排序 | 不并列,依次递增 | 分页、去重、唯一ID |
RANK | 排序 | 并列跳号 1,1,3 | 成绩排名(有空缺) | |
DENSE_RANK | 排序 | 并列不跳 1,1,2 | 排行榜连续排名 | |
NTILE(N) | 排序 | 按桶分配 | 数据分层、等频分箱 | |
| 偏移 | LAG(expr,N) | 排序 | — | 环比增长、与上期对比 |
LEAD(expr,N) | 排序 | — | 与下期对比、提前预警 | |
| 聚合 | SUM OVER | 排序+帧 | — | 累计/移动求和 |
AVG OVER | 排序+帧 | — | 移动平均、趋势平滑 | |
COUNT OVER | 排序+帧 | — | 累计计数、滑动计数 | |
MAX OVER | 排序+帧 | — | 历史峰值 | |
MIN OVER | 排序+帧 | — | 历史谷值 | |
| 首尾定位 | FIRST_VALUE | 排序+帧 | — | 首单金额、偏离度基准 |
LAST_VALUE | 排序+帧 | — | 最近一次记录(需注意默认帧陷阱) | |
NTH_VALUE | 排序+帧 | — | 第 N 条记录、第 N 高值 | |
| 分布 | CUME_DIST | 排序 | 并列同值 | 累积覆盖比例 |
PERCENT_RANK | 排序 | 并列同值 | 相对排名位置 |
延伸阅读
- 窗口函数从入门到精通 — 语法、窗口帧、排序等基础概念
- 窗口函数可视化播放器 — 亲手调试每个算子的执行过程
- 窗口函数面试真题 — 字节/阿里/腾讯高频考题
- Spark SQL 函数速查 — 417 个内置函数手册
「数据仓库技术」文章同步更新,不错过每一篇干货

备注「数据仓库技术」加入社群,每日一道大厂SQL真题
